Release 2 (9.2)
Part Number A96583-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle C++ Call Interface Programmer's Guide Release 2 (9.2) Part Number A96583-01 |
|
This chapter provides information on how to implement object-relational programming using the Oracle C++ Call Interface (OCCI).
The following topics are discussed:
OCCI supports both the associative and navigational style of data access. Traditionally, third-generation language (3GL) programs manipulate data stored in a database by using the associative access based on the associations organized by relational database tables. In associative access, data is manipulated by executing SQL statements and PL/SQL procedures. OCCI supports associative access to objects by enabling your applications to execute SQL statements and PL/SQL procedures on the database server without incurring the cost of transporting data to the client.
Object-oriented programs that use OCCI can also make use of navigational access that is a key aspect of this programming paradigm. Applications model their objects as a set of interrelated objects that form graphs of objects, the relationships between objects implemented as references (REFs). Typically, an object application that uses navigational access first retrieves one or more objects from the database server by issuing a SQL statement that returns REFs to those objects. The application then uses those REFs to traverse related objects, and perform computations on these other objects as required. Navigational access does not involve executing SQL statements except to fetch the references of an initial set of objects. By using OCCI's API for navigational access, your application can perform the following functions on Oracle objects:
This chapter gives examples that show you how to create a persistent object, access an object, modify an object, and flush the changes to the database server. It discusses how to access the object using both navigational and associative approaches.
Many of the programming principles that govern a relational OCCI application are the same for an object-relational application. An object-relational application uses the standard OCCI calls to establish database connections and process SQL statements. The difference is that the SQL statements that are issued retrieve object references, which can then be manipulated with OCCI's object functions. An object can also be directly manipulated as a value (without using its object reference).
Instances of an Oracle type are categorized into persistent objects and transient objects based on their lifetime. Instances of persistent objects can be further divided into standalone objects and embedded objects depending on whether or not they are referenced by way of an object identifier.
A persistent object is an object which is stored in an Oracle database. It may be fetched into the object cache and modified by an OCCI application. The lifetime of a persistent object can exceed that of the application which is accessing it. Once it is created, it remains in the database until it is explicitly deleted. There are two types of persistent objects:
It is also possible to select a referenceable object, in which case you fetch the object by value instead of fetching it by reference.
Embedded objects may also be referred to as nonreferenceable objects or value instances. You may sometimes see them referred to as values, which is not to be confused with scalar data values. The context should make the meaning clear.
The following SQL examples demonstrate the difference between these two types of persistent objects.
This code example demonstrates how a standalone object is created:
CREATE TYPE person_t AS OBJECT (name varchar2(30), age number(3)); CREATE TABLE person_tab OF person_t;
Objects that are stored in the object table person_tab are standalone objects. They have object identifiers and can be referenced. They can be pinned in an OCCI application.
This code example demonstrates how an embedded object is created:
CREATE TABLE department (deptno number, deptname varchar2(30), manager person_t);
Objects which are stored in the manager column of the department table are embedded objects. They do not have object identifiers, and they cannot be referenced. This means they cannot be pinned in an OCCI application, and they also never need to be unpinned. They are always retrieved into the object cache by value.
A transient object is an instance of an object type. Its lifetime cannot exceed that of the application. The application can also delete a transient object at any time.
The Object Type Translator (OTT) utility generates two operator new methods for each C++ class, as demonstrated in this code example:
class Person : public PObject { . . . public: dvoid *operator new(size_t size); // creates transient instance dvoid *operator new(size_t size, Connection &conn, string table); // creates persistent instance }
The following code example demonstrates how a transient object can be created:
Person *p = new Person();
Transient objects cannot be converted to persistent objects. Their role is fixed at the time they are instantiated.
See Also:
|
In the context of this manual, a value refers to either:
The context should make it clear which meaning is intended.
|
Note: It is possible to |
Before an OCCI application can work with object types, those types must exist in the database. Typically, you create types with SQL DDL statements, such as CREATE TYPE.
The following sections discuss how persistent and transient objects are created.
Before you create a persistent object, you must have created the environment and opened a connection. The following example shows how to create a persistent object, addr, in the database table, addr_tab, created by means of a SQL statement:
CREATE TYPE ADDRESS AS OBJECT (state CHAR(2), zip_code CHAR(5)); CREATE TABLE ADDR_TAB of ADDRESS; ADDRESS *addr = new(conn, "ADDR_TAB") ADDRESS("CA", "94065");
The persistent object is created in the database only when one of the following occurs:
Connection::commit())Connection::flushCache())PObject::flush())An instance of the transient object ADDRESS is created in the following manner:
ADDRESS *addr_trans = new ADDRESS("MD", "94111");
When your C++ application retrieves instances of object types from the database, it needs to have a client-side representation of the objects. The Object Type Translator (OTT) utility generates C++ class representations of database object types for you. For example, consider the following declaration of a type in your database:
CREATE TYPE address AS OBJECT (state CHAR(2), zip_code CHAR(5));
The OTT utility produces the following C++ class:
class ADDRESS : public PObject { protected: string state; string zip; public: void *operator new(size_t size); void *operator new(size_t size, const Session* sess, const string& table); string getSQLTypeName(size_t size); ADDRESS(void *ctx) : PObject(ctx) { }; static void *readSQL(void *ctx); virtual void readSQL(AnyData& stream); static void writeSQL(void *obj, void *ctx); virtual void writeSQL(AnyData& stream); }
These class declarations are automatically written by OTT to a header (.h) file that you name. This header file is included in the source files for an application to provide access to objects. Instances of a PObject (as well as instances of classes derived from PObjects) can be either transient or persistent. The methods writeSQL and readSQL are used internally by the OCCI object cache to linearize and delinearize the objects and are not to be used or modified by OCCI clients.
See Also:
|
This section discusses the steps involved in developing a basic OCCI object application.
The basic structure of an OCCI application that uses objects is similar to a relational OCCI application, the difference being object functionality. The steps involved in an OCCI object program include:
Environment. Initialize the OCCI programming environment in object mode.
Your application will most likely need to include C++ class representations of database objects in a header file. You can create these classes by using the Object Type Translator (OTT) utility, as described in Chapter 7, "How to Use the Object Type Translator Utility".
REF) to an object.REF) from the database server and pin the object. You can then perform some or all of the following:
See Also:
|
Figure 3-1 shows a simple program logic flow for how an application might work with objects. For simplicity, some required steps are omitted.
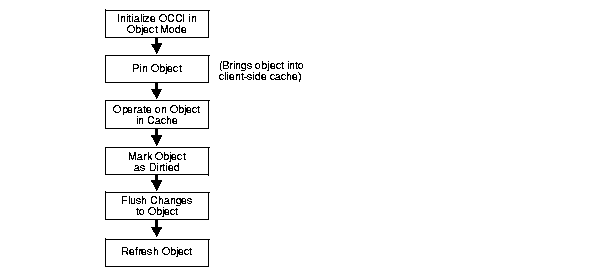
The steps shown in Figure 3-1 are discussed in the following sections:
If your OCCI application accesses and manipulates objects, then it is essential that you specify a value of OBJECT for the mode parameter of the createEnvironment method, the first call in any OCCI application. Specifying this value for mode indicates to OCCI that your application will be working with objects. This notification has the following important effects:
The following code example demonstrates how to specify the OBJECT mode when creating an OCCI environment:
Environment *env; Connection *con; Statement *stmt; env = Environment::createEnvironment(Environment::OBJECT); con = env->createConnection(userName, password, connectString);
Your application does not have to allocate memory when database objects are loaded into the object cache. The object cache provides transparent and efficient memory management for database objects. When database objects are loaded into the object cache, they are transparently mapped into the host language (C++) representation.
The object cache maintains the association between the object copy in the object cache and the corresponding database object. Upon commit, changes made to the object copy in the object cache are automatically propagated back to the database.
The object cache maintains a look-up table for mapping references to objects. When an application dereferences a reference to an object and the corresponding object is not yet cached in the object cache, the object cache automatically sends a request to the database server to fetch the object from the database and load it into the object cache. Subsequent dereferences of the same reference are faster since they are to the object cache itself and do not incur a round-trip to the database server.
Subsequent dereferences of the same reference fetch from the cache instead of requiring a round-trip. The exception to this is in the case of a dereferencing operation that occurs just after a commit. In this case, the latest object copy from the server is returned. This is an enhancement in this release that ensures that the latest object from the database is cached after each transaction.
The object cache maintains a pin count for each persistent object in the object cache. When an application dereferences a reference to an object, the pin count of the object pointed to by the reference is incremented. The subsequent dereferencing of the same reference to the object does not change the pin count. Until the reference to the object goes out of scope, the object will continue to be pinned in the object cache and be accessible by the OCCI client.
The pin count functions as a reference count for the object. The pin count of the object becomes zero (0) only when there are no more references referring to this object, during which time the object becomes eligible for garbage collection. The object cache uses a least recently used algorithm to manage the size of the object cache. This algorithm frees objects with a pin count of 0 when the object cache reaches the maximum size.
In most situations, OCCI users do not need to explicitly pin or unpin the objects because the object cache automatically keeps track of the pin counts of all the objects in the cache. As explained earlier, the object cache increments the pin count when a reference points to the object and decrements it when the reference goes out of scope or no longer points to the object.
But there is one exception. If an OCCI application uses Ref<T>::ptr() method to get a pointer to the object, then the pin and unpin methods of the PObject class can be used by the application to control pinning and unpinning of the objects in the object cache.
Note that the object cache does not manage the contents of object copies; it does not automatically refresh object copies. Your application must ensure the validity and consistency of object copies.
Whenever changes are made to object copies in the object cache, your application is responsible for flushing the changed object to the database.
Memory for the object cache is allocated on demand when objects are loaded into the object cache.
The client-side object cache is allocated in the program's process space. This object cache is the memory for objects that have been retrieved from the database server and are available to your application.
|
Note: If you initialize the OCCI environment in object mode, your application allocates memory for the object cache, whether or not the application actually uses object calls. |
There is only one object cache allocated for each OCCI environment. All objects retrieved or created through different connections within the environment use the same physical object cache. Each connection has its own logical object cache.
For objects retrieved into the cache by dereferencing a reference, you should not perform an explicit delete. For such objects, the pin count is incremented when a reference is dereferenced for the first time and decremented when the reference goes out of scope. When the pin count of the object becomes 0, indicating that all references to that object are out of scope, the object is automatically eligible for garbage collection and subsequently deleted from the cache.
For persistent objects that have been created by calling the new operator, you must call a delete if you do not commit the transaction. Otherwise, the object is garbage collected after the commit. This is because when such an object is created using new, its pin count is initially 0. However, because the object is dirty it remains in the cache. After a commit, it is no longer dirty and thus garbage collected. Therefore, a delete is not required.
If a commit is not performed, then you must explicitly call delete to destroy that object. You can do this as long as there are no references to that object. For transient objects, you must delete explicitly to destroy the object.
You should not call a delete operator on a persistent object. A persistent object that is not marked/dirty is freed by the garbage collector when its pin count is 0. However, for transient objects you must delete explicitly to destroy the object.
The object cache has two important associated parameters:
These parameters refer to levels of cache memory usage, and they help to determine when the cache automatically "ages out" eligible objects to free up memory.
If the memory occupied by the objects currently in the cache reaches or exceeds the maximum cache size, the cache automatically begins to free (or age out) unmarked objects which have a pin count of zero. The cache continues freeing such objects until memory usage in the cache reaches the optimal size, or until it runs out of objects eligible for freeing.
The maximum object cache size (in bytes) is computed by incrementing the optimal cache size (optimal_size) by the maximum cache size percentage (max_size_percentage), as follows:
Maximum cache size = optimal_size + optimal_size * max_size_percentage / 100
The default value for the maximum cache size percentage is 10%. The default value for the optimal cache size is 8MB.
These parameters can be set or retrieved using the following member functions of the Environment class:
void setCacheMaxSize(unsigned int maxSize);unsigned int getCacheMaxSize() const;void setCacheOptSize(unsigned int OptSize);unsigned int getCacheOptSize() const;
See Also:
|
You can employ SQL within OCCI to retrieve objects, and to perform DML operations:
See Also:
|
In the previous sections we discussed navigational access, where SQL is used only to fetch the references of an initial set of objects and then navigate from them to the other objects. Here we will discuss how to fetch the objects using SQL.
The following example shows how to use the ResultSet::getObject method to fetch objects through associative access where it gets each object from the table, addr_tab, using SQL:
string sel_addr_val = "SELECT VALUE(address) FROM ADDR_TAB address"; ResultSet *rs = stmt->executeQuery(sel_addr_val); while (rs->next()) { ADDRESS *addr_val = rs->getObject(1); cout << "state: " << addr_val->getState(); }
The objects fetched through associative access are termed value instances and they behave just like transient objects. Methods such as markModified, flush, and markDeleted are applicable only for persistent objects.
Any changes made to these objects are not reflected in the database.
We have just seen how to use SQL to access objects. OCCI also provides the ability to use SQL to insert new objects or modify existing objects in the database server through the Statement::setObject method interface.
The following example creates a transient object Address and inserts it into the database table addr_tab:
ADDRESS *addr_val = new address("NV", "12563"); // new a transient instance stmt->setSQL("INSERT INTO ADDR_TAB values(:1)"); stmt->setObject(1, addr_val); stmt->execute();
By using navigational access, you engage in a series of operations:
See Also:
|
In order to work with objects, your application must first retrieve one or more objects from the database server. You accomplish this by issuing a SQL statement that returns references (REFs) to one or more objects.
|
Note: It is also possible for a SQL statement to fetch embedded objects, rather than |
The following SQL statement retrieves a REF to a single object address from the database table addr_tab:
string sel_addr = "SELECT REF(address) FROM addr_tab address WHERE zip_code = '94065'";
The following code example illustrates how to execute the query and fetch the REF from the result set.
ResultSet *rs = stmt->executeQuery(sel_addr); rs->next(); Ref<address> addr_ref = rs->getRef(1);
At this point, you could use the object reference to access and manipulate the object or objects from the database.
See Also:
|
Upon completion of the fetch step, your application has a REF to an object. The actual object is not currently available to work with. Before you can manipulate an object, it must be pinned. Pinning an object loads the object into the object cache, and enables you to access and modify the object's attributes and follow references from that object to other objects. Your application also controls when modified objects are written back to the database server.
|
Note: This section deals with a simple pin operation involving a single object at a time. For information about retrieving multiple objects through complex object retrieval, see the section Overview of Complex Object Retrieval. |
OCCI requires only that you dereference the REF in the same way you would dereference any C++ pointer. Dereferencing the REF transparently materializes the object as a C++ class instance.
Continuing the Address class example from the previous section, assume that the user has added the following method:
string Address::getState() { return state; }
To dereference this REF and access the object's attributes and methods:
string state = addr_ref->getState(); // -> pins the object
The first time Ref<T> (addr_ref) is dereferenced, the object is pinned, which is to say that it is loaded into the object cache from the database server. From then on, the behavior of operator -> on Ref<T> is just like that of any C++ pointer (T *). The object remains in the object cache until the REF (addr_ref) goes out of scope. It then becomes eligible for garbage collection.
Now that the object has been pinned, your application can modify that object.
Manipulating object attributes is no different from that of accessing them as shown in the previous section. Let us assume the Address class has the following user defined method that sets the state attribute to the input value:
void Address::setState(string new_state) { state = new_state; }
The following example shows how to modify the state attribute of the object, addr:
addr_ref->setState("PA");
As explained earlier, the first invocation of the operator -> on Ref<T> loads the object if not already in the object cache.
In the example in the previous section, an attribute of an object was changed. At this point, however, that change exists only in the client-side cache. The application must take specific steps to ensure that the change is written to the database.
The first step is to indicate that the object has been modified. This is done by calling the markModified method on the object (derived method of PObject). This method marks the object as dirty (modified).
Continuing the previous example, after object attributes are manipulated, the object referred to by addr_ref can be marked dirty as follows:
addr_ref->markModified()
Objects that have had their dirty flag set must be flushed to the database server for the changes to be recorded in the database. This can be done in three ways:
flush, a derived method of PObject.Connection::flushCache method. In this case, OCCI traverses the dirty list maintained by the object cache and flushes all the dirty objects.Connection::commit method. Doing so also traverses the dirty list and flushes the objects to the database server. The dirty list includes newly created persistent objects.The object cache has two important parameters associated with it which are properties of environment handle:
These parameters refer to levels of cache memory usage and they help to determine when the cache automatically ages out eligible objects to make memory available.
If the amount of memory occupied by the objects that are currently in the cache reaches or exceeds the high water mark, then the cache automatically begins to free unmarked objects that have a pin count of 0. The cache continues freeing such objects until memory use in the cache is optimized, or until there are no more objects in the cache that are eligible for freeing.
OCCI provides set and get methods in environments that allow you to set and get the cache maximum/optimal sizes. The maximum cache size is specified as a percentage of cache optimal size. The maximum cache size in bytes is computed as follows:
maximum_cache_size = optimal_size + optimal_size * max_size_percentage/100
The default value for cache maximum size is 10% and the default value for cache optimal size is 8MB. When a persistent object is created through the overloaded PObject::new operator, the newly created object is marked dirty and its pin count is 0.
"Pin Object" describes how pin count of an object functions as a reference count and how an unmarked object with a 0 pin count can become eligible for garbage collection. In the case of a newly created persistent object, the object is unmarked after the transaction is committed or aborted and if the object has a 0 pin count, in other words there are no references referring to it. The object then becomes a candidate for being aged out.
As described in the previous section, dereferencing a Ref<T> for the first time results in the object being loaded into the object cache from the database server. From then on, the behavior of operator -> on Ref<T> is the same as any C++ pointer and it provides access to the object copy in the cache. But once the transaction commits or aborts, the object copy in the cache can no longer be valid because it could be modified by any other client. Therefore, after the transaction ends, when the Ref<T> is again dereferenced, the object cache recognizes the fact that the object is no longer valid and fetches the most up-to-date copy from the database server.
In the examples discussed earlier, only a single object was fetched or pinned at a time. In these cases, each pin operation involved a separate database server round-trip to retrieve the object.
Object-oriented applications often model their problems as a set of interrelated objects that form graphs of objects. These applications process objects by starting with some initial set of objects and then using the references in these objects to traverse the remaining objects. In a client/server setting, each of these traversals could result in costly network round-trips to fetch objects.
The performance of such applications can be increased through the use of complex object retrieval (COR). This is a prefetching mechanism in which an application specifies some criteria (content and boundary) for retrieving a set of linked objects in a single network round-trip.
|
Note: Using COR does not mean that these prefetched objects are pinned. They are fetched into the object cache, so that subsequent pin calls are local operations. |
A complex object is a set of logically related objects consisting of a root object, and a set of objects each of which is prefetched based on a given depth level. The root object is explicitly fetched or pinned. The depth level is the shortest number of references that need to be traversed from the root object to a given prefetched object in a complex object.
An application specifies a complex object by describing its content and boundary. The fetching of complex objects is constrained by an environment's prefetch limit, the amount of memory in the object cache that is available for prefetching objects.
|
Note: The use of complex object retrieval does not add functionality; it only improves performance, and so its use is optional. |
An OCCI application can achieve COR by setting the appropriate attributes of a Ref<T> before dereferencing it using the following methods:
// prefetch attributes of the specified type name up to the the specified depth Ref<T>::setPrefetch(const string &typeName, unsigned int depth); // prefetch all the attribute types up to the specified depth. Ref<T>::setPrefetch(unsigned int depth);
The application can also choose to fetch all objects reachable from the root object by way of REFs (transitive closure) to a certain depth. To do so, set the level parameter to the depth desired. For the preceding two examples, the application could also specify (PO object REF, OCCI_MAX_PREFETCH_DEPTH) and (PO object REF, 1) respectively to prefetch required objects. Doing so results in many extraneous fetches but is quite simple to specify, and requires only one database server round-trip.
As an example for this discussion, consider the following type declaration:
CREATE TYPE customer(...); CREATE TYPE line_item(...); CREATE TYPE line_item_varray as VARRAY(100) of REF line_item; CREATE TYPE purchase_order AS OBJECT ( po_number NUMBER, cust REF customer, related_orders REF purchase_order, line_items line_item_varray)
The purchase_order type contains a scalar value for po_number, a VARRAY of line_items, and two references. The first is to a customer type and the second is to a purchase_order type, indicating that this type may be implemented as a linked list.
When fetching a complex object, an application must specify the following:
REF attributes should be followed for COR, and the depth level indicates how many levels deep those links should be followed.In the case of the purchase_order object in the preceding example, the application must specify the following:
purchase_order objectcustomer, purchase_order, or line_itemAn application prefetching a purchase order will very likely need access to the customer information for that purchase order. Using simple navigation, this would require two database server accesses to retrieve the two objects.
Through complex object retrieval, customer can be prefetched when the application pins the purchase_order object. In this case, the complex object would consist of the purchase_order object and the customer object it references.
In the previous example, if the application wanted to prefetch a purchase order and the related customer information, the application would specify the purchase_order object and indicate that customer should be followed to a depth level of one as follows:
Ref<PURCHASE_ORDER> poref; poref.setPrefetch("CUSTOMER",1);
If the application wanted to prefetch a purchase order and all objects in the object graph it contains, the application would specify the purchase_order object and indicate that both customer and purchase_order should be followed to the maximum depth level possible as follows:
Ref<PURCHASE_ORDER> poref; poref.setPrefetch("CUSTOMER", OCCI_MAX_PREFETCH_DEPTH); poref.setPrefetch("PURCHASE_ORDER", OCCI_MAX_PREFETCH_DEPTH);
where OCCI_MAX_PREFETCH_DEPTH specifies that all objects of the specified type reachable through references from the root object should be prefetched.
If an application wanted to prefetch a purchase order and all the line items associated with it, the application would specify the purchase_order object and indicate that line_items should be followed to the maximum depth level possible as follows:
Ref<PURCHASE_ORDER> poref; poref.setPrefetch("LINE_ITEM", 1);
After specifying and fetching a complex object, subsequent fetches of objects contained in the complex object do not incur the cost of a network round-trip, because these objects have already been prefetched and are in the object cache. Keep in mind that excessive prefetching of objects can lead to a flooding of the object cache. This flooding, in turn, may force out other objects that the application had already pinned leading to a performance degradation instead of performance improvement.
The SELECT privilege is needed for all prefetched objects. Objects in the complex object for which the application does not have SELECT privilege will not be prefetched.
Oracle supports two kinds of collections - variable length arrays (ordered collections) and nested tables (unordered collections). OCCI maps both of them to a Standard Template Library (STL) vector container, giving you the full power, flexibility, and speed of an STL vector to access and manipulate the collection elements. The following is the SQL DDL to create a VARRAY and an object that contains an attribute of type VARRAY.
CREATE TYPE ADDR_LIST AS VARRAY(3) OF REF ADDRESS; CREATE TYPE PERSON AS OBJECT (name VARCHAR2(20), addr_l ADDR_LIST);
Here is the C++ class declaration generated by OTT:
class PERSON : public PObject { protected: string name; vector< Ref< ADDRESS > > addr_1; public: void *operator new(size_t size); void *operator new(size_t size, const Session* sess, const string& table); string getSQLTypeName(size_t size); PERSON (void *ctx) : PObject(ctx) { }; static void *readSQL(void *ctx); virtual void readSQL(AnyData& stream); static void writeSQL(void *obj, void *ctx); virtual void writeSQL(AnyData& stream); }
See Also:
|
If your application needs to fetch an embedded object--an object stored in a column of a regular table, rather than an object table--you cannot use the REF retrieval mechanism. Embedded instances do not have object identifiers, so it is not possible to get a reference to them. This means that they cannot serve as the basis for object navigation. There are still many situations, however, in which an application will want to fetch embedded instances.
For example, assume that an address type has been created.
CREATE TYPE address AS OBJECT ( street1 varchar2(50), street2 varchar2(50), city varchar2(30), state char(2), zip number(5))
You could then use that type as the datatype of a column in another table:
CREATE TABLE clients ( name varchar2(40), addr address)
Your OCCI application could then issue the following SQL statement:
SELECT addr FROM clients WHERE name='BEAR BYTE DATA MANAGEMENT'
This statement would return an embedded address object from the clients table. The application could then use the values in the attributes of this object for other processing. The application should execute the statement and fetch the object in the same way as described in the section "Overview of Associative Access".
If a column in a row of a database table has no value, then that column is said to be NULL, or to contain a NULL. Two different types of NULLs can apply to objects:
Atomic nullness is not the same thing as nonexistence. An atomically NULL object still exists, its value is just not known. It may be thought of as an existing object with no data.
For every type of object attribute, OCCI provides a corresponding class. For instance, NUMBER attribute type maps to the Number class, REF maps to RefAny, and so on. Each and every OCCI class that represents a data type provides two methods:
Similarly, these methods are inherited from the PObject class by all the objects and can be used to access and set atomically null information about them.
OCCI provides the application with the flexibility to access the contents of the objects using their pointers or their references. OCCI provides the PObject::getRef method to return a reference to a persistent object. This call is valid for persistent objects only.
OCCI users can use the overloaded PObject::operator new to create the persistent objects. It is the user's responsibility to free the object by calling the PObject::operator delete method.
Note that freeing the object from the object cache is different from deleting the object from the database server. To delete the object from the database server, the user needs to call the PObject::markDelete method. The operator delete just frees the object and reclaims the memory in the object cache but it does not delete the object from the database server.
Type inheritance of objects has many similarities to inheritance in C++ and Java. You can create an object type as a subtype of an existing object type. The subtype is said to inherit all the attributes and methods (member functions and procedures) of the supertype, which is the original type. Only single inheritance is supported; an object cannot have more than one supertype. The subtype can add new attributes and methods to the ones it inherits. It can also override (redefine the implementation) of any of its inherited methods. A subtype is said to extend (that is, inherit from) its supertype.
See Also:
|
As an example, a type Person_t can have a subtype Student_t and a subtype Employee_t. In turn, Student_t can have its own subtype, PartTimeStudent_t. A type declaration must have the flag NOT FINAL so that it can have subtypes. The default is FINAL, which means that the type can have no subtypes.
All types discussed so far in this chapter are FINAL. All types in applications developed before release 9.0 are FINAL. A type that is FINAL can be altered to be NOT FINAL. A NOT FINAL type with no subtypes can be altered to be FINAL. Person_t is declared as NOT FINAL for our example:
CREATE TYPE Person_t AS OBJECT ( ssn NUMBER, name VARCAHR2(30), address VARCHAR2(100)) NOT FINAL;
A subtype inherits all the attributes and methods declared in its supertype. It can also declare new attributes and methods, which must have different names than those of the supertype. The keyword UNDER identifies the supertype, like this:
CREATE TYPE Student_t UNDER Person_t ( deptid NUMBER, major VARCHAR2(30)) NOT FINAL;
The newly declared attributes deptid and major belong to the subtype Student_t. The subtype Employee_t is declared as, for example:
CREATE TYPE Employee_t UNDER Person_t ( empid NUMBER, mgr VARCHAR2(30));
See Also:
|
This subtype Student_t, can have its own subtype, such as PartTimeStudent_t:
CREATE TYPE PartTimeStuden_t UNDER Student_t ( numhours NUMBER) ;
See Also:
|
The benefits of polymorphism derive partially from the property substitutability. Substitutability allows a value of some subtype to be used by code originally written for the supertype, without any specific knowledge of the subtype being needed in advance. The subtype value behaves to the surrounding code just like a value of the supertype would, even if it perhaps uses different mechanisms within its specializations of methods.
Instance substitutability refers to the ability to use an object value of a subtype in a context declared in terms of a supertype. REF substitutability refers to the ability to use a REF to a subtype in a context declared in terms of a REF to a supertype.
REF type attributes are substitutable, that is, an attribute defined as REF T can hold a REF to an instance of T or any of its subtypes.
Object type attributes are substitutable, that is, an attribute defined to be of (an object) type T can hold an instance of T or any of its subtypes.
Collection element types are substitutable, that is, if we define a collection of elements of type T, then it can hold instances of type T and any of its subtypes. Here is an example of object attribute substitutability:
CREATE TYPE Book_t AS OBJECT ( title VARCHAR2(30), author Person_t /* substitutable */);
Thus, a Book_t instance can be created by specifying a title string and a Person_t (or any subtype of Person_t) object:
Book_t(`My Oracle Experience', Employee_t(12345, `Joe', `SF', 1111, NULL))
A type can be declared NOT INSTANTIABLE, which means that there is no constructor (default or user defined) for the type. Thus, it will not be possible to construct instances of this type. The typical usage would be to define instantiable subtypes for such a type. Here is how this property is used:
CREATE TYPE Address_t AS OBJECT(...) NOT INSTANTIABLE NOT FINAL; CREATE TYPE USAddress_t UNDER Address_t(...); CREATE TYPE IntlAddress_t UNDER Address_t(...);
A method of a type can be declared to be NOT INSTANTIABLE. Declaring a method as NOT INSTANTIABLE means that the type is not providing an implementation for that method. Further, a type that contains any NOT INSTANTIABLE methods must necessarily be declared as NOT INSTANTIABLE. For example:
CREATE TYPE T AS OBJECT ( x NUMBER, NOT INSTANTIABLE MEMBER FUNCTION func1() RETURN NUMBER ) NOT INSTANTIABLE;
A subtype of NOT INSTANTIABLE can override any of the NOT INSTANTIABLE methods of the supertype and provide concrete implementations. If there are any NOT INSTANTIABLE methods remaining, the subtype must also necessarily be declared as NOT INSTANTIABLE.
A NOT INSTANTIABLE subtype can be defined under an instantiable supertype. Declaring a NOT INSTANTIABLE type to be FINAL is not useful and is not allowed.
The following calls support type inheritance.
This method provides information specific to inherited types. Additional attributes have been added for the properties of inherited types. For example, you can get the supertype of a type.
The setRef, setObject and setVector methods of the Statement class are used to bind REF, object, and collections respectively. All these functions support REF, instance, and collection element substitutability. Similarly, the corresponding getxxx methods to fetch the data also support substitutability.
Class declarations for objects with inheritance are similar to the simple object declarations except that the class is derived from the parent type class and only the fields corresponding to attributes not already in the parent class are included. The structure for these declarations is as follows:
class <typename> : public <parentTypename> { protected: <OCCItype1> <attributename1>; . . . <OCCItypen> <attributenamen>; public: void *operator new(size_t size); void *operator new(size_t size, const Session* sess, const string& table); string getSQLTypeName(size_t size); <typename> (void *ctx) : <parentTypename>(ctx) { }; static void *readSQL(void *ctx); virtual void readSQL(AnyData& stream); static void writeSQL(void *obj, void *ctx); virtual void writeSQL(AnyData& stream); }
In this structure, all the variables are the same as in the simple object case. parentTypename refers to the name of the parent type, that is, the class name of the type from which typename inherits.
Following is a sample OCCI application that uses some of the features discussed in this chapter.
First we list the SQL DDL and then the OTT mappings.
CREATE TYPE FULL_NAME AS OBJECT (first_name CHAR(20), last_name CHAR(20)); CREATE TYPE ADDRESS AS OBJECT (state CHAR(20), zip CHAR(20)); CREATE TYPE ADDRESS_TAB AS VARRAY(3) OF REF ADDRESS; CREATE TYPE PERSON AS OBJECT (id NUMBER, name FULL_NAME, curr_addr REF ADDRESS, prev_addr_l ADDRESS_TAB); CREATE TYPE STUDENT UNDER PERSON (school_name CHAR(20));
Let us assume OTT generates FULL_NAME, ADDRESS, PERSON, and PFGRFDENT class declarations in demo.h. The following sample OCCI application will extend the classes generated by OTT and will add some user defined methods.
/************************* myDemo.h *****************************************/ #include demo.h // declarations for the MyFullName class. class MyFullname : public FULLNAME { public: MyFullname(string first_name, string last_name); void displayInfo(); } // declarations for the MyAddress class. class MyAddress : public ADDRESS { public: MyAddress(string state_i, string zip_i); void displayInfo(); } // declarations for the MyPerson class. class MyPerson : public PERSON { public: MyPerson(Number id_i, MyFullname *name_i, Ref<MyAddress>& addr_i); void move(const Ref<MyAddress>& new_addr); void displayInfo(); } /**************************myDemo.cpp*************************************/ /* initialize MyFullName */ MyFullName::MyFullname(string first_name, string last_name) : FirstName(first_name), LastName(last_name) { } /* display all the information in MyFullName */ void MyFullName::displayInfo() { cout << "FIRST NAME is" << FirstName << endl; cout << "LAST NAME is" << LastName << endl; } /*********************************************************************/ // method implementations for MyAddress class. /********************************************************************/ /* initialize MyAddress */ MyAddress::MyAddress(string state_i, string zip_i) : state(state_i), zip(zip_i) { } /* display all the information in MyAddress */ void MyAddress::displayInfo() { cout << "STATE is" << state << endl; cout << "ZIP is" << zip << endl; } /*********************************************************************/ // method implementations for MyPerson class. /********************************************************************/ /* initialize MyPerson */ MyPerson::MyPerson(Number id_i, MyFullName* name_i, const Ref<MyAddress>& addr_i) : id(id_i), name(name_i), curr_addr(addr_i) { } /* Move Person from curr_addr to new_addr */ void MyPerson::move(const Ref<MyAddress>& new_addr) { prev_addr_l.push_back(curr_addr); // append curr_addr to the vector curr_addr = new_addr; this->mark_modified(); // mark the object as dirty } /* Display all the information of MyPerson */ void MyPerson::displayInfo() { cout << "ID is" << CPerson::id << endl; name->displayInfo(); // de-referencing the Ref attribute using -> operator curr_addr->displayInfo(); cout << "Prev Addr List: " << endl; for (int i = 0; i < prev_addr_l.size(); i++) { // access the collection elements using [] operator prev_addr_l[i]->displayInfo(); } } /************************************************************************/ // main function of this OCCI application. // This application connects to the database as scott/tiger, creates // the Person (Joe Black) whose Address is in CA, and commits the changes. // The Person object is then retrieved from the database and its // information is displayed. A second Address object is created (in PA), // then the previously retrieved Person object (Joe Black) is moved to // this new address. The Person object is then displayed again. /***********************************************************************/ int main() { Environment *env = Environment::createEnvironment() Connection *conn = env->createConnection("scott", "tiger"); /* Call the OTT generated function to register the mappings */ RegisterMappings(env); /* create a persistent object of type ADDRESS in the database table, ADDR_TAB */ MyAddress *addr1 = new(conn, "ADDR_TAB") MyAddress("CA", "94065"); MyFullName name1("Joe", "Black"); /* create a persistent object of type Person in the database table, PERSON_TAB */ MyPerson *person1 = new(conn, "PERSON_TAB") MyPerson(1,&name1,addr1->getRef()); /* commit the transaction which results in the newly created objects, addr, person1 being flushed to the server */ conn->commit(); Statement *stmt = conn->createStatement(); ResultSet *resultSet = stmt->executeQuery("SELECT REF(Person) from person_tab where id = 1"); ResultSetMetaData rsMetaData = resultSet->getMetaData(); if (Types::POBJECT != rsMetaData.getColumnType(1)) return -1; Ref<MyPerson> joe_ref = (Ref<MyPerson>) resultSet.getRef(1); joe_ref->displayInfo(); /* create a persistent object of type ADDRESS, in the database table, ADDR_TAB */ MyAddress *new_addr1 = new(conn, "ADDR_TAB") MyAddress("PA", "92140"); joe_ref->move(new_addr1->getRef()); joe_ref->displayInfo(); /* commit the transaction which results in the newly created object, new_addr and the dirty object, joe to be flushed to the server. Note that joe was marked dirty in move(). */ conn->commit(); /* The following delete statements delete the objects only from the application cache. To delete the objects from server, mark_deleted() should be used. */ delete addr1; delete person1; delete new_addr1; conn->closeStatement(stmt); env->terminateConnection(conn); Environment::terminateEnvironment(env); return 0; }
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

