Release 2 (9.2)
Part Number A96595-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Cartridge Developer's Guide Release 2 (9.2) Part Number A96595-01 |
|
In addition to the efficient and secure management of data ordered under the relational model, Oracle now also provides support for data organized under the object model. Object types and other features such as large objects (LOBs), external procedures, extensible indexing and query optimization can be used to build powerful, reusable server-based components called data cartridges.
This chapter introduces the following introductory information about data cartridges:
Within the framework of the Oracle Extensibility Architecture, data cartridges are the mechanism for extending the capabilities of the Oracle server. What does this mean?
First, Oracle lets you capture the business logic and processes associated with domain-specific data in user-defined datatypes. In some cases, where the data cartridge provides new behavior without needing new attributes, the vehicle of implementation may be packages rather than formal types. Once you have defined these types using either of these approaches, Oracle enables you to determine the manner in which the server interprets, stores, retrieves, and indexes the data. Ultimately, data cartridges are the means to package this functionality as software components that can then be plugged into a server to extend its capabilities into a new domain.
This is all possible because the database has itself been made extensible. That is, you can now customize the indexing and query optimization mechanisms of the database management system for user-defined business objects and rich types. Where the native implementation of indexing and query optimization service could be improved for some specialized processing you require, you can provide your own implementations of these services. You use the extensibility interfaces to register your implementations with the server. Registering them causes the server to use your implementations instead its own when doing your specialized processing.
This is all possible because the database has itself been made extensible. That is, you can now customize the database management system so that it treats user-defined business objects and rich types on a par with native types with regard to server mechanisms such as indexing and query optimization.
The extensibility interfaces consist of functions that the server calls as needed to execute pieces of the custom indexing or optimizing behavior implemented for a data cartridge. The interfaces are defined by Oracle; you, the cartridge developer, must actually implement the functions (also frequently called interfaces) to embody the specialized behavior you require. In general, you implement the functions as static methods of an object type. An object type that implements the extensible indexing interface is called an indextype; an object type that implements the extensible optimizing interface is called a statistics type.
The key characteristics of data cartridges are as follows:
Person with a column Photo of type Image.Over the years, virtually every industry has evolved sophisticated models to handle complex data objects that make up the essence of their business. By data objects, we mean both the structures that relate different units of information and the operations that are performed on them.
The simple names given these data objects often conceal considerable complexity of the expertise they embody. For example, the banking industry has many different types of bank accounts. Each bank account has customer demographic information, balance information, transaction information, and rules that embody its behavior (deposit, withdrawal, interest accrual, and so forth).
As the following sections describe, data cartridges allow you to leverage this expertise by encapsulating this business logic in software components that integrate with the Oracle server. The notion of adding logic to data in a database has been available for some time by way of stored procedures. With the addition of object-relational extensions, the Oracle server can now be enhanced by application programmers and independent software vendors to support a new generation of data types, processes, and logic in order to model business objects.
At the same time as business models have led to the development of increasingly complex data objects, the revolution in information technology has made it necessary to work with new kinds of data: satellites images, X-rays, animal sounds, seismic vibrations, chemical models -- all these complex and multimedia datatypes are now forms of information that have to be stored and retrieved, queried and analyzed.
Today's web-based applications routinely include many different kinds of complex data. The ability to extend the database to include application-specific data types as well as the business logic associated with these types requires a new class of networked, content-rich, multitiered, distributed applications. As the following sections describe, data cartridges allow you to meet this need by combining scalar and unstructured datatypes in domain-specific components. You can further combine these components to provide both horizontal (across industries) and vertical (niche specific) functionality.
The complexity of data objects, which may entail the need to handle specialized data, gives rise to application domains. Put another way: a data cartridge is typically domain-specific. Domains are characterized by content and scope.
In terms of content, a data cartridge can accommodate either scalar data or complex and multimedia forms of data. Scalar data is data that can be modeled using native SQL types such as INTEGER, NUMBER, or CHAR. Complex forms of data include matrixes, temperature and magnetic grids, and compound documents. Multimedia types include video, voice, and image data.
In terms of scope, a data cartridge can have broad horizontal (cross-industry) coverage or it can be specialized for a specific type of business. For example, a data cartridge for general storage and retrieval of textual data is cross-industry in scope, whereas a data cartridge for the storage and retrieval of legal documents for litigation support is industry-specific.
Table 1-1 shows a way of classifying data cartridge domains according to their content (type of data) and scope (cross-industry or industry-specific), with some examples.
Following from this, you can see that another way of viewing the relationship of cartridges to domains is to view basic multimedia datatypes as forming a foundation that can be extended in specific ways by specific industries. For example, Table 1-3 shows cartridges that could be built for medical applications:
| Text | Image | Audio | Video | Spatial |
|---|---|---|---|---|
|
Records |
MRI |
Heartbeat |
Teaching |
Demographic Analysis |
A cartridge providing basic services may be deployed across many industries, as a text cartridge may be utilized within both law and medicine. A cartridge can also leverage domain expertise across an industry, as an image cartridge may provide basic functionality for both X-rays and Sonar within medicine. These cartridges can in turn be further extended for more specialized vertical applications. For instance, any of the cartridges mentioned previously could be specialized by being extended by other cartridges:
| Image |
|---|
|
Image -> MRI -> Brain MRI -> Neonatal Brain MRI |
In other words, you can develop a cartridge for both horizontal and vertical market penetration.
In summary: data cartridges allow you to define new datatypes and behavior which can then provide, in component form, solution-oriented capabilities previously unavailable in the server. In some cases, where the data cartridge provides new behavior without needing new attributes, the data cartridge may provide PL/SQL packages but not new datatype definitions. Users of data cartridges can freely use the new datatypes in their application to take advantage of the new behavior. For example, after an image data cartridge is installed, you can define a table called Person with a Photo column of type Image
The Oracle server provides services for basic data storage, query processing, optimization, and indexing. Various applications use these services to access database capabilities. However, data cartridges have specialized needs because they incorporate domain-specific data. To accommodate these specialized applications, the basic services have been made extensible.
That is, where some aspects of a standard Oracle service are not adequate for the processing a data cartridge requires, you as the data cartridge developer can provide services that are specially tuned to your cartridge. Every data cartridge can provide its own implementations of these services. These specialized implementations are registered with the server using the Oracle extensibility interfaces.
For example, suppose you want to build a spatial data cartridge for geographical information systems (GIS) applications. In this case, you may need to implement routines that create a spatial index, insert an entry into the index, update the index, delete from the index, and perform any other required operations. To do this you would register your implementations with the Oracle server using extensible indexing interface, and then the server will invoke your implementation every time indexing operations were needed for spatial data. In effect, you extend the indexing service of the server.
Figure 1-1 shows the standard services implemented by the Oracle server. This section describes some of these services, not to provide exhaustive descriptions but to highlight major Oracle capabilities as they relate to data cartridge development.
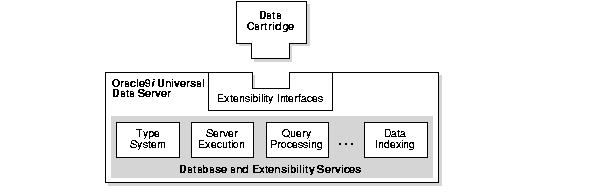
The Oracle universal data server provides both native and extensible type system services. Historically, mainstream applications have focused on accessing and modifying corporate data that is stored in tables composed of native SQL datatypes, such as INTEGER, NUMBER, DATE, and CHAR. Oracle adds support for new types, including:
REF (relationship)BFILE (external file)This section discusses these new types.
An object type differs from native SQL datatypes in that it is user-defined and it specifies both the underlying persistent data (attributes) and the related behaviors (methods). Object types are used to extend the modeling capabilities provided by the native datatypes. You can use object types to make better models of complex entities in the real world by binding data attributes to semantic behaviors.
An object type can have one or more attributes. Each attribute has a name and a type. The type of an attribute can be a native SQL type, a LOB, a collection, another object type, or a REF type. The syntax for defining object types is discussed in Chapter 3.
A method is a procedure or a function that is part of an object type definition. Methods can access and manipulate attributes of the related object type. Methods can run within the execution environment of the Oracle server. Methods can also be dispatched outside the server as part of the extensible server execution environment.
Collections are SQL datatypes that contain multiple elements. Each element, or value, for a collection is the same datatype. In Oracle, collections of complex types can be VARRAYs or nested tables.
A VARRAY contains a variable number of ordered elements. The VARRAY datatype can be used for a column of a table or an attribute of an object type. The element type of a VARRAY can be either a native datatype, such as NUMBER, or an object type.
A nested table can be created using Oracle SQL to provide the semantics of an unordered collection. As with a VARRAY, a nested table can be used to define a column of a table or an attribute of an object type.
If you create an object table in Oracle, you can obtain a reference that acts as a database pointer to an associated row object. References are important for navigating among object instances, particularly in client-side applications.
The REF operator obtains a reference to a row object. Because REFs rely on the underlying object identity, you can use REF only with an object stored as a row in an object table or objects composed from an object view.
For further information about the REF operator and examples of its use, see the chapter on object types in the PL/SQL User's Guide and Reference.
Oracle provides large object (LOB) types to handle the storage demands of images, video clips, documents, and other forms of non-structured data. For an extensive coverage of Large Objects, please see Oracle9i Application Developer's Guide - Large Objects (LOBs). Large objects are stored in a way that optimizes space utilization and provides efficient access. Large objects are composed of locators and the related binary or character data. The LOB locators are stored in-line with other table columns and, for internal LOBs (BLOB, CLOB, and NCLOB), the data can be in a separate database storage area. For external LOBs (BFILE), the data is stored outside the database tablespaces in operating system files. A table can contain multiple LOB columns (in contrast to the limit of one LONG RAW column for each table). Each LOB column can be stored in a separate tablespace, and even on different secondary storage devices.
Oracle SQL data definition language (DDL) extensions let you create, modify, and delete tables and object types that contain large objects (LOBs). The Oracle SQL data manipulation language (DML) includes statements to insert and delete complete LOBs. There is also an extensive set of statements for piece-wise reading, writing, and manipulating of LOBs with PL/SQL and the Oracle Call Interface (OCI) software.
For internal LOB types, both the locators and related data participate fully in the transactional model of the Oracle server. The data for BFILEs does not participate in transactions; however, BFILE locators are fully supported by Oracle server transactions. For more information about LOBs and transactions, see the Oracle9i Application Developer's Guide - Large Objects (LOBs).
Unlike scalar quantities, a LOB value cannot be indexed using built-in indexing schemes. However, you can use the various LOB APIs to build modules, including methods of object types, to access and manipulate LOB content. The extensible indexing framework lets you define the semantics of data residing in LOBs and manipulate the data using these semantics.
Oracle provides you a variety of interfaces and environments to access and manipulate LOBs, which are described in great detail in Oracle9i Application Developer's Guide - Large Objects (LOBs).The use of LOBs to store and manipulate binary and character data to represent your domain is discussed Chapter 6, "Working with Multimedia Datatypes".
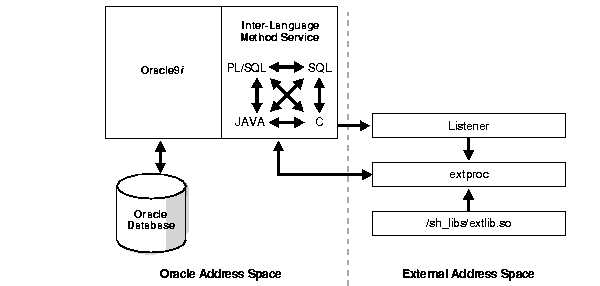
The Oracle type system decouples the implementation of a member method for an object type from the specification of the method. Components of an Oracle data cartridge can be implemented using any of the popular programming languages. In Oracle, methods, functions, and procedures can be developed using PL/SQL, external C language routines, or Java. Thus, the database server runtime environment can be extended by user-defined methods, functions, and procedures.
In Oracle, Java offers data cartridge developers a powerful implementation choice for data cartridge behavior. In addition, PL/SQL offers a data cartridge developer a powerful procedural language that supports all the object extensions for SQL. With PL/SQL, program logic can execute on the server and perform traditional procedural language operations such as loops, if-then-else clauses, and array access.
While PL/SQL and Java are powerful, certain computation-intensive operations such as a Fast Fourier Transform or an image format conversion are handled more efficiently by C programs. With the Oracle Server, you can call C language programs from the server. Such programs are executed as in a separate address space than the server. This ensures that the database server is insulated from any program failures that might occur in external procedures and, under no circumstances, can an Oracle database be corrupted by such failures.
With certain reasonable restrictions, external procedures can call back to the Oracle Server using OCI. Callbacks are particularly useful for processing LOBs. For example, by using callbacks an external procedure can perform piece-wise reads or writes of LOBs stored in the database. External procedures can also use callbacks to manipulate domain indexes stored as Index-Organized Tables in the database.
Typical database management systems support a few types of access methods (B+Trees, Hash Indexes) on a limited set of data types (numbers, strings, and so on). For simple data types such as integers and small strings, all aspects of indexing can be easily handled by the database system. In recent years, however, databases are being used to store different types of data such as text, spatial, image, video and audio that require content-based retrieval. This raises the need for indexing complex data types and also specialized indexing techniques.
Complex data types have application-specific formats, indexing requirements, and selection predicates. For example, there are many different means of document encoding (ODA, XML, plain text) and information retrieval techniques (keyword, full-text boolean, similarity, probabilistic, and so on). Similarly, R-trees are an efficient method of indexing spatial data. No database server can be built with support for all possible kinds of complex data and indexing. Oracle's solution is to build an extensible server which lets you define new index types as required.
Such user-defined indexes are called domain indexes because they index data in an application-specific domain. The cartridge is responsible for defining the index structure, maintaining the index content during load and update operations, and searching the index during query processing. The physical index can be stored in the Oracle database as tables or externally as a file.
A domain index is a schema object. It is created, managed, and accessed by routines implemented as methods of a user-defined object type, called an indextype. The routines that an indextype must implement, and the kinds of things that the routines must do, are described in this document. Actual implementation of the routines is specific to an application and so must be done by the cartridge developer. Once a new indextype is implemented by a data cartridge, Oracle uses the indextype's specialized implementation of these routines for the data cartridge instead of the indexing implementation native to the server.
With extensible indexing, the application
When the database system handles the physical storage of domain indexes, data cartridges
Typical relational and object-relational database management systems do not support extensible indexing. Consequently, many applications maintain file-based indexes for complex data residing in relational database tables. A considerable amount of code and effort is required to maintain consistency between external indexes and the related relational data, support compound queries (involving tabular values and external indexes), and to manage a system (backup, recovery, allocate storage, and so on) with multiple forms of persistent storage (files and databases). By supporting extensible indexes, the Oracle Server significantly reduces the level of effort needed to develop solutions involving high-performance access to complex datatypes.
The extensible optimizer functionality allows authors of user-defined functions and indexes to create statistics collection, selectivity, and cost functions. This information is used by the optimizer in choosing a query plan. The cost-based optimizer is thus extended to use the user-supplied information; the rule-based optimizer is unchanged.
The optimizer generates an execution plan for a SQL statement. An execution plan includes an access method for each table in the FROM clause, and an ordering (called the join order) of the tables in the FROM clause. System-defined access methods include indexes, hash clusters, and table scans. The optimizer chooses a plan by generating a set of join orders or permutations, computing the cost of each, and selecting the one with the lowest cost. For each table in the join order, the optimizer computes the cost of each possible access method and join method and chooses the one with the lowest cost. The cost of the join order is the sum of the access method and join method costs. The costs are calculated using algorithms which together compose the cost model. A cost model can include varying level of detail about the physical environment in which the query is executed. Our present cost model includes only the number of disk accesses with minor adjustments to compensate for the lack of detail. The optimizer uses statistics about the objects referenced in the query to compute the costs. The statistics are gathered using the ANALYZE command. The optimizer uses these statistics to calculate cost and selectivity. The selectivity of a predicate is the fraction of rows in a table that will be chosen by the predicate. It is a number between 0 and 100 (expressed as percentage).
Extensible indexing functionality allows users to define new operators, index types, and domain indexes. For such user-defined operators and domain indexes, the extensible optimizer functionality will allow users to control the three main components used by the optimizer to select an execution plan: statistics, selectivity, and cost.
|
Note: Oracle Corporation recommends that you use the See Oracle9i Supplied PL/SQL Packages and Types Reference for information about |
Extensibility interfaces fall into the following classes:
The DBMS interfaces are the simplest kind of extensibility services. DBMS interfaces are made available through extensions to SQL or to the Oracle Call Interface (OCI). For example, the extensible type manager utilizes the CREATE TYPE syntax in SQL. Similarly, extensible indexing uses DDL and DML support for specifying and manipulating indexes.
Generic interfaces provide basic services like memory management, context management, internationalization, and cartridge-specific management. These cartridge basic interface services are used by data cartridges to implement behavior for new datatypes in the context of the server's execution environment. These services provide helper routines that make it easy for data cartridge developers to write robust, portable server-side methods.
Sometimes the DBMS needs to call the data cartridge functions for implementations provided by the data cartridge developer. So, for user-defined indexing, the DBMS must use the implementation of the index interface whenever an index search or fetch operation is performed. For user-defined query optimization, the query optimizer must call functions implemented by the data cartridge to compute cost of user-defined operators or functions.
These standard data cartridge functions are similar to callback functions that the DBMS can invoke. In the future, data cartridge interfaces will be made available to enable the data cartridge to include the specifications for such functions.
The accumulated expertise that underlies a set of data objects comprises a knowledge base that can be marketed as a standalone cartridge, or as a cartridge that could be extended in different ways by different users. But how does one achieve this? The data and rules that apply to the software components are often spread across many different applications. With data cartridges, you gather the definition and rules together for use throughout the data processing environment. Packaging domain-specific component expertise in a data cartridge allows the cartridge to access the corporate information repository and add both organizational and operational value to the data. Such software components are applications that can be "plugged" into other software components, and which are themselves "pluggable".
Their constituents reside at the server or are accessed from the server. Most processing for data cartridges occurs at the server or is dispatched from the server in the form of an external procedure.
A data cartridge generally defines one or more object types. Object types from this and potentially other data cartridges can provide users with new or extended capabilities conveniently packaged. A data cartridge includes both the definition of object types and the code that implements their capabilities. A data cartridge can be used as the foundation for the definition of other data cartridges.
Each object type includes two components. The order in which these components are made available to the server (that is, the order in which they are defined) is important. The major components include:
In addition, a data cartridge may use the extended server execution environment. The use of external procedures involves two additional components:
Simple data cartridges consist of these components, which are described in this section. More complex data cartridges will use the extensibility services and interfaces (see Chapter 9, "Using Cartridge Services"). Complex Data Cartridges contain domain operators and domain indextypes (see Chapter 7, "Building Domain Indexes"), and optimization functions (see Chapter 8, "Query Optimization").
A data cartridge consists of one or more of these domain-specific objects packaged and integrated with the server. Each domain-specific type is an object type (or ODT, for object data type) and includes both of the following:
Attributes can be defined using built-in datatypes or other object types.
Methods can be simple (such as adding two numbers) or complex (such as computing prices of financial derivatives), and can be coded either in PL/SQL or in a third-generation language (3GL) such as C.
The object type specification gives the object a name, and it defines the types of persistent data, called attributes, that an instance of this object will include. It also specifies names, return values, and argument types of the related behaviors, or methods. Much like a C++ class definition in a header (.h) prefix file, the type specification lays out the object framework (attributes and method signatures), but does not include the actual method code that performs the functions. The object type specifications for the various object types defined by your data cartridge will be written in SQL and stored in a SQL script that will be input to the server at cartridge installation time.
The type body provides the code that implements the object type's methods. Method code can be implemented in PL/SQL, Java, C, C++, or any other 3GL. Most simple methods can be written in PL/SQL and Java. (See the PL/SQL User's Guide and Reference for a complete discussion of PL/SQL syntax.)
Code written in C, C++, and other 3GLs must be packaged in a runtime or dynamic link library. This is described in "External Library Linkage Specification" and "External Library Code".
If the implementation of your methods is in C, C++, or some other 3GL, the methods must be packaged within a runtime or dynamic link library. The external library linkage specification is necessary to tell the server about this library, including its location, the binding of the type's methods to the library's entry points, and the methods' parameters.
Any 3GL code dispatched through the external library linkage specification will run in a separate process from the Oracle server. As such, the dispatch involves communication overhead. In deciding which methods should be implemented in external libraries, you should be aware of this overhead. In general, the cost of dispatch is less significant for methods that are complex or computation intensive.
The external library is the runtime or dynamic link library that contains any 3GL method code. You implement the 3GL methods in a language such as C, and then use operating-system-specific commands to build a shared-object library on UNIX platforms or a DLL on Windows NT systems.
Data cartridges are packaged so that their constituents (type definitions, PL/SQL packages, external procedures, users, roles, synonyms, and so forth) can be installed into or de-installed from the Oracle universal data server as a unit.
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

