Release 2 (9.2)
Part Number A96520-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Warehousing Guide Release 2 (9.2) Part Number A96520-01 |
|
This chapter introduces you to the use of materialized views and discusses:
Typically, data flows from one or more online transaction processing (OLTP) databases into a data warehouse on a monthly, weekly, or daily basis. The data is normally processed in a staging file before being added to the data warehouse. Data warehouses commonly range in size from tens of gigabytes to a few terabytes. Usually, the vast majority of the data is stored in a few very large fact tables.
One technique employed in data warehouses to improve performance is the creation of summaries. Summaries are special kinds of aggregate views that improve query execution times by precalculating expensive joins and aggregation operations prior to execution and storing the results in a table in the database. For example, you can create a table to contain the sums of sales by region and by product.
The summaries or aggregates that are referred to in this book and in literature on data warehousing are created in Oracle using a schema object called a materialized view. Materialized views can perform a number of roles, such as improving query performance or providing replicated data.
Prior to Oracle8i, organizations using summaries spent a significant amount of time and effort creating summaries manually, identifying which summaries to create, indexing the summaries, updating them, and advising their users on which ones to use. The introduction of summary management in Oracle8i eased the workload of the database administrator and meant the user no longer needed to be aware of the summaries that had been defined. The database administrator creates one or more materialized views, which are the equivalent of a summary. The end user queries the tables and views at the detail data level. The query rewrite mechanism in the Oracle server automatically rewrites the SQL query to use the summary tables. This mechanism reduces response time for returning results from the query. Materialized views within the data warehouse are transparent to the end user or to the database application.
Although materialized views are usually accessed through the query rewrite mechanism, an end user or database application can construct queries that directly access the summaries. However, serious consideration should be given to whether users should be allowed to do this because any change to the summaries will affect the queries that reference them.
In data warehouses, you can use materialized views to precompute and store aggregated data such as the sum of sales. Materialized views in these environments are often referred to as summaries, because they store summarized data. They can also be used to precompute joins with or without aggregations. A materialized view eliminates the overhead associated with expensive joins and aggregations for a large or important class of queries.
In distributed environments, you can use materialized views to replicate data at distributed sites and to synchronize updates done at those sites with conflict resolution methods. The materialized views as replicas provide local access to data that otherwise would have to be accessed from remote sites. Materialized views are also useful in remote data marts.
| See Also:
Oracle9i Replication and Oracle9i Heterogeneous Connectivity Administrator's Guide for details on distributed and mobile computing |
You can also use materialized views to download a subset of data from central servers to mobile clients, with periodic refreshes and updates between clients and the central servers.
This chapter focuses on the use of materialized views in data warehouses.
| See Also:
Oracle9i Replication and Oracle9i Heterogeneous Connectivity Administrator's Guide for details on distributed and mobile computing |
You can use materialized views in data warehouses to increase the speed of queries on very large databases. Queries to large databases often involve joins between tables, aggregations such as SUM, or both. These operations are expensive in terms of time and processing power. The type of materialized view you create determines how the materialized view is refreshed and used by query rewrite.
You can use materialized views in a number of ways, and you can use almost identical syntax to perform a number of roles. For example, a materialized view can replicate data, a process formerly achieved by using the CREATE SNAPSHOT statement. Now CREATE MATERIALIZED VIEW is a synonym for CREATE SNAPSHOT.
Materialized views improve query performance by precalculating expensive join and aggregation operations on the database prior to execution and storing the results in the database. The query optimizer automatically recognizes when an existing materialized view can and should be used to satisfy a request. It then transparently rewrites the request to use the materialized view. Queries go directly to the materialized view and not to the underlying detail tables. In general, rewriting queries to use materialized views rather than detail tables improves response. Figure 8-1 illustrates how query rewrite works.
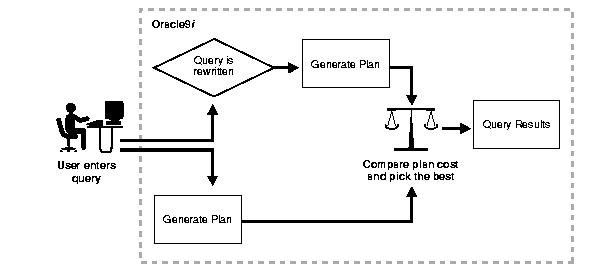
When using query rewrite, create materialized views that satisfy the largest number of queries. For example, if you identify 20 queries that are commonly applied to the detail or fact tables, then you might be able to satisfy them with five or six well-written materialized views. A materialized view definition can include any number of aggregations (SUM, COUNT(x), COUNT(*), COUNT(DISTINCT x), AVG, VARIANCE, STDDEV, MIN, and MAX). It can also include any number of joins. If you are unsure of which materialized views to create, Oracle provides a set of advisory procedures in the DBMS_OLAP package to help in designing and evaluating materialized views for query rewrite. These functions are also known as the Summary Advisor or the Advisor. Note that the OLAP Summary Advisor is different. See Oracle9i OLAP User's Guide for further details regarding the OLAP Summary Advisor.
If a materialized view is to be used by query rewrite, it must be stored in the same database as the fact or detail tables on which it relies. A materialized view can be partitioned, and you can define a materialized view on a partitioned table. You can also define one or more indexes on the materialized view.
Unlike indexes, materialized views can be accessed directly using a SELECT statement.
|
Note: The techniques shown in this chapter illustrate how to use materialized views in data warehouses. Materialized views can also be used by Oracle Replication. See Oracle9i Replication for further information. |
Summary management consists of:
DBMS_OLAP package. Collectively, these functions are called the Summary Advisor, and are also available as part of Oracle Enterprise Manager.
| See Also:
Chapter 16, "Summary Advisor" and Oracle9i OLAP User's Guide for OLAP-related schemas |
Many large decision support system (DSS) databases have schemas that do not closely resemble a conventional data warehouse schema, but that still require joins and aggregates. The use of summary management features imposes no schema restrictions, and can enable some existing DSS database applications to improve performance without the need to redesign the database or the application.
Figure 8-2 illustrates the use of summary management in the warehousing cycle. After the data has been transformed, staged, and loaded into the detail data in the warehouse, you can invoke the summary management process. First, use the Advisor to plan how you will use summaries. Then, create summaries and design how queries will be rewritten.
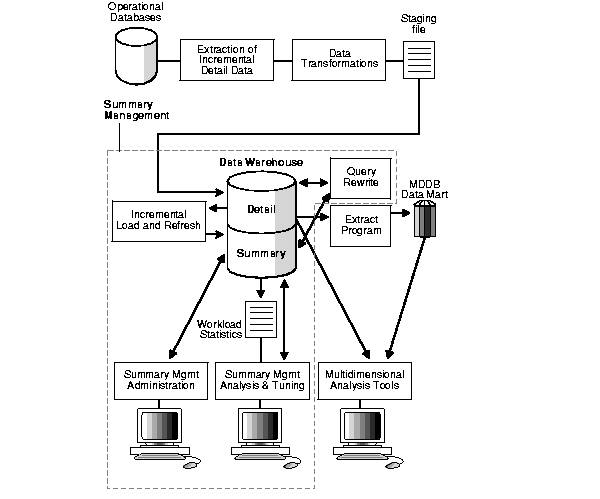
Understanding the summary management process during the earliest stages of data warehouse design can yield large dividends later in the form of higher performance, lower summary administration costs, and reduced storage requirements.
Some basic data warehousing terms are defined as follows:
Dimension tables usually change slowly over time and are not modified on a periodic schedule. They are used in long-running decision support queries to aggregate the data returned from the query into appropriate levels of the dimension hierarchy.
The vast majority of data in a data warehouse is stored in a few very large fact tables that are updated periodically with data from one or more operational OLTP databases.
Fact tables include facts (also called measures) such as sales, units, and inventory.
fact.sales.fact.revenues - fact.expenses.fact_a.revenues - fact_b.expenses.Fact tables also contain one or more foreign keys that organize the business transactions by the relevant business entities such as time, product, and market. In most cases, these foreign keys are non-null, form a unique compound key of the fact table, and each foreign key joins with exactly one row of a dimension table.
Summary management can perform many useful functions, including query rewrite and materialized view refresh, even if your data warehouse design does not follow these guidelines. However, you will realize significantly greater query execution performance and materialized view refresh performance benefits and you will require fewer materialized views if your schema design complies with these guidelines.
A materialized view definition includes any number of aggregates, as well as any number of joins. In several ways, a materialized view behaves like an index:
In the case of normalized or partially normalized dimension tables (a dimension that is stored in more than one table), identify how these tables are joined. Note whether the joins between the dimension tables can guarantee that each child-side row joins with one and only one parent-side row. In the case of denormalized dimensions, determine whether the child-side columns uniquely determine the parent-side (or attribute) columns. These relationships can be enabled with constraints, using the NOVALIDATE and RELY options if the relationships represented by the constraints are guaranteed by other means. Note that if the joins between fact and dimension tables do not support the parent-child relationship described previously, you still gain significant performance advantages from defining the dimension with the CREATE DIMENSION statement. Another alternative, subject to some restrictions, is to use outer joins in the materialized view definition (that is, in the CREATE MATERIALIZED VIEW statement).
You must not create dimensions in any schema that does not satisfy these relationships. Incorrect results can be returned from queries otherwise.
| See Also:
Chapter 9, "Dimensions" and Oracle9i OLAP User's Guide for OLAP-related schemas |
Before starting to define and use the various components of summary management, you should review your schema design to abide by the following guidelines wherever possible.
Guidelines 1 and 2 are more important than guideline 3. If your schema design does not follow guidelines 1 and 2, it does not then matter whether it follows guideline 3. Guidelines 1, 2, and 3 affect both query rewrite performance and materialized view refresh performance.
| Schema Guideline | Description |
|---|---|
|
Dimensions |
Dimensions should either be denormalized (each dimension contained in one table) or the joins between tables in a normalized or partially normalized dimension should guarantee that each child-side row joins with exactly one parent-side row. The benefits of maintaining this condition are described in "Creating Dimensions". You can enforce this condition by adding |
|
Dimensions |
If dimensions are denormalized or partially denormalized, hierarchical integrity must be maintained between the key columns of the dimension table. Each child key value must uniquely identify its parent key value, even if the dimension table is denormalized. Hierarchical integrity in a denormalized dimension can be verified by calling the |
|
Dimensions |
Fact and dimension tables should similarly guarantee that each fact table row joins with exactly one dimension table row. This condition must be declared, and optionally enforced, by adding |
|
Incremental Loads |
Incremental loads of your detail data should be done using the SQL*Loader direct-path option, or any bulk loader utility that uses Oracle's direct-path interface. This includes |
|
Partitions |
Range/composite partition your tables by a monotonically increasing time column if possible (preferably of type |
|
Dimensions |
After each load and before refreshing your materialized view, use the |
|
Time Dimensions |
If a time dimension appears in the materialized view as a time column, partition and index the materialized view in the same manner as you have the fact tables. |
If you are concerned with the time required to enable constraints and whether any constraints might be violated, use the ENABLE NOVALIDATE with the RELY clause to turn on constraint checking without validating any of the existing constraints. The risk with this approach is that incorrect query results could occur if any constraints are broken. Therefore, as the designer, you must determine how clean the data is and whether the risk of wrong results is too great.
A popular and efficient way to load data into a warehouse or data mart is to use SQL*Loader with the DIRECT or PARALLEL option or to use another loader tool that uses the Oracle direct-path API.
| See Also:
Oracle9i Database Utilities for the restrictions and considerations when using SQL*Loader with the |
Loading strategies can be classified as one-phase or two-phase. In one-phase loading, data is loaded directly into the target table, quality assurance tests are performed, and errors are resolved by performing DML operations prior to refreshing materialized views. If a large number of deletions are possible, then storage utilization can be adversely affected, but temporary space requirements and load time are minimized. The DML that may be required after one-phase loading causes multitable aggregate materialized views to become unusable in the safest rewrite integrity level.
In a two-phase loading process:
INSERT AS SELECT with the PARALLEL or APPEND hint.NOVALIDATE option.Immediately after loading the detail data and updating the indexes on the detail data, the database can be opened for operation, if desired. You can disable query rewrite at the system level by issuing an ALTER SYSTEM SET QUERY_REWRITE_ENABLED = false statement until all the materialized views are refreshed.
If QUERY_REWRITE_INTEGRITY is set to stale_tolerated, access to the materialized view can be allowed at the session level to any users who do not require the materialized views to reflect the data from the latest load by issuing an ALTER SESSION SET QUERY_REWRITE_INTEGRITY=true statement. This scenario does not apply when QUERY_REWRITE_INTEGRITY is either enforced or trusted because the system ensures in these modes that only materialized views with updated data participate in a query rewrite.
The motivation for using materialized views is to improve performance, but the overhead associated with materialized view management can become a significant system management problem. When reviewing or evaluating some of the necessary materialized view management activities, consider some of the following:
After the initial effort of creating and populating the data warehouse or data mart, the major administration overhead is the update process, which involves:
The update process must generally be performed within a limited period of time known as the update window. The update window depends on the update frequency (such as daily or weekly) and the nature of the business. For a daily update frequency, an update window of two to six hours might be typical.
You need to know your update window for the following activities:
The SELECT clause in the materialized view creation statement defines the data that the materialized view is to contain. Only a few restrictions limit what can be specified. Any number of tables can be joined together. However, they cannot be remote tables if you wish to take advantage of query rewrite. Besides tables, other elements such as views, inline views (subqueries in the FROM clause of a SELECT statement), subqueries, and materialized views can all be joined or referenced in the SELECT clause.
The types of materialized views are:
In data warehouses, materialized views normally contain aggregates as shown in Example 8-1. For fast refresh to be possible, the SELECT list must contain all of the GROUP BY columns (if present), and there must be a COUNT(*) and a COUNT(column) on any aggregated columns. Also, materialized view logs must be present on all tables referenced in the query that defines the materialized view. The valid aggregate functions are: SUM, COUNT(x), COUNT(*), AVG, VARIANCE, STDDEV, MIN, and MAX, and the expression to be aggregated can be any SQL value expression.
Fast refresh for a materialized view containing joins and aggregates is possible after any type of DML to the base tables (direct load or conventional INSERT, UPDATE, or DELETE). It can be defined to be refreshed ON COMMIT or ON DEMAND. A REFRESH ON COMMIT, materialized view will be refreshed automatically when a transaction that does DML to one of the materialized view's detail tables commits. The time taken to complete the commit may be slightly longer than usual when this method is chosen. This is because the refresh operation is performed as part of the commit process. Therefore, this method may not be suitable if many users are concurrently changing the tables upon which the materialized view is based.
Here are some examples of materialized views with aggregates. Note that materialized view logs are only created because this materialized view will be fast refreshed.
CREATE MATERIALIZED VIEW LOG ON products WITH SEQUENCE, ROWID (prod_id, prod_name, prod_desc, prod_subcategory, prod_subcat_desc, prod_ category, prod_cat_desc, prod_weight_class, prod_unit_of_measure, prod_pack_ size, supplier_id, prod_status, prod_list_price, prod_min_price) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON sales WITH SEQUENCE, ROWID (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW product_sales_mv PCTFREE 0 TABLESPACE demo STORAGE (INITIAL 8k NEXT 8k PCTINCREASE 0) BUILD IMMEDIATE REFRESH FAST ENABLE QUERY REWRITE AS SELECT p.prod_name, SUM(amount_sold) AS dollar_sales, COUNT(*) AS cnt, COUNT(amount_sold) AS cnt_amt FROM sales s, products p WHERE s.prod_id = p.prod_id GROUP BY prod_name;
Example 8-1 creates a materialized view product_sales_mv that computes total number and value of sales for a product. It is derived by joining the tables sales and products on the column prod_id. The materialized view is populated with data immediately because the build method is immediate and it is available for use by query rewrite. In this example, the default refresh method is FAST, which is allowed because the appropriate materialized view logs have been created on tables product and sales.
CREATE MATERIALIZED VIEW product_sales_mv PCTFREE 0 TABLESPACE demo STORAGE (INITIAL 16k NEXT 16k PCTINCREASE 0) BUILD DEFERRED REFRESH COMPLETE ON DEMAND ENABLE QUERY REWRITE AS SELECT p.prod_name, SUM(amount_sold) AS dollar_sales FROM sales s, products p WHERE s.prod_id = p.prod_id GROUP BY p.prod_name;
Example 8-2 creates a materialized view product_sales_mv that computes the sum of sales by prod_name. It is derived by joining the tables store and fact on the column store_key. The materialized view does not initially contain any data, because the build method is DEFERRED. A complete refresh is required for the first refresh of a build deferred materialized view. When it is refreshed and once populated, this materialized view can be used by query rewrite.
CREATE MATERIALIZED VIEW LOG ON sales WITH SEQUENCE, ROWID (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW sum_sales PARALLEL BUILD IMMEDIATE REFRESH FAST ON COMMIT AS SELECT s.prod_id, s.time_id, COUNT(*) AS count_grp, SUM(s.amount_sold) AS sum_dollar_sales, COUNT(s.amount_sold) AS count_dollar_sales, SUM(s.quantity_sold) AS sum_quantity_sales, COUNT(s.quantity_sold) AS count_quantity_sales FROM sales s GROUP BY s.prod_id, s.time_id;
Example 8-3 creates a materialized view that contains aggregates on a single table. Because the materialized view log has been created, the materialized view is fast refreshable. If DML is applied against the sales table, then the changes will be reflected in the materialized view when the commit is issued.
Table 8-1 illustrates the aggregate requirements for materialized views.
Note that COUNT(*) must always be present. Oracle recommends that you include the optional aggregates in column Z in the materialized view in order to obtain the most efficient and accurate fast refresh of the aggregates.
Some materialized views contain only joins and no aggregates, such as in Example 8-4, where a materialized view is created that joins the sales table to the times and customers tables. The advantage of creating this type of materialized view is that expensive joins will be precalculated.
Fast refresh for a materialized view containing only joins is possible after any type of DML to the base tables (direct-path or conventional INSERT, UPDATE, or DELETE).
A materialized view containing only joins can be defined to be refreshed ON COMMIT or ON DEMAND. If it is ON COMMIT, the refresh is performed at commit time of the transaction that does DML on the materialized view's detail table. Oracle does not allow self-joins in materialized join views.
If you specify REFRESH FAST, Oracle performs further verification of the query definition to ensure that fast refresh can be performed if any of the detail tables change. These additional checks are:
SELECT list of the materialized view query definition.WHERE clause. However, if there are outer joins, the WHERE clause cannot have any selections. Further, if there are outer joins, all the joins must be connected by ANDs and must use the equality (=) operator.If some of these restrictions are not met, you can create the materialized view as REFRESH FORCE to take advantage of fast refresh when it is possible. If one of the tables did not meet all of the criteria, but the other tables did, the materialized view would still be fast refreshable with respect to the other tables for which all the criteria are met.
A materialized view log should contain the rowid of the master table. It is not necessary to add other columns.
To speed up refresh, you should create indexes on the materialized view's columns that store the rowids of the fact table.
CREATE MATERIALIZED VIEW LOG ON sales WITH ROWID; CREATE MATERIALIZED VIEW LOG ON times WITH ROWID; CREATE MATERIALIZED VIEW LOG ON customers WITH ROWID; CREATE MATERIALIZED VIEW detail_sales_mv PARALLEL BUILD IMMEDIATE REFRESH FAST AS SELECT s.rowid "sales_rid", t.rowid "times_rid", c.rowid "customers_rid", c.cust_id, c.cust_last_name, s.amount_sold, s.quantity_sold, s.time_id FROM sales s, times t, customers c WHERE s.cust_id = c.cust_id(+) AND s.time_id = t.time_id(+);
In this example, to perform a fast refresh, UNIQUE constraints should exist on c.cust_id and t.time_id. You should also create indexes on the columns sales_rid, times_rid, and customers_rid, as illustrated in the following. This will improve the refresh performance.
CREATE INDEX mv_ix_salesrid ON detail_sales_mv("sales_rid");
Alternatively, if the previous example did not include the columns times_rid and customers_id, and if the refresh method was REFRESH FORCE, then this materialized view would be fast refreshable only if the sales table was updated but not if the tables times or customers were updated.
CREATE MATERIALIZED VIEW detail_sales_mv PARALLEL BUILD IMMEDIATE REFRESH FORCE AS SELECT s.rowid "sales_rid", c.cust_id, c.cust_last_name, s.amount_sold, s.quantity_sold, s.time_id FROM sales s, times t, customers c WHERE s.cust_id = c.cust_id(+) AND s.time_id = t.time_id(+);
A nested materialized view is a materialized view whose definition is based on another materialized view. A nested materialized view can reference other relations in the database in addition to referencing materialized views.
In a data warehouse, you typically create many aggregate views on a single join (for example, rollups along different dimensions). Incrementally maintaining these distinct materialized aggregate views can take a long time, because the underlying join has to be performed many times.
Using nested materialized views, you can create multiple single-table materialized views based on a joins-only materialized view and the join is performed just once. In addition, optimizations can be performed for this class of single-table aggregate materialized view and thus refresh is very efficient.
You can create a nested materialized view on materialized views that contain joins only or joins and aggregates.
All the underlying objects (materialized views or tables) on which the materialized view is defined must have a materialized view log. All the underlying objects are treated as if they were tables. All the existing options for materialized views can be used, with the exception of ON COMMIT REFRESH, which is not supported for a nested materialized views that contains joins and aggregates.
Using the tables and their columns from the sh sample schema, the following materialized views illustrate how nested materialized views can be created.
/* create the materialized view logs */ CREATE MATERIALIZED VIEW LOG ON sales WITH ROWID; CREATE MATERIALIZED VIEW LOG ON customers WITH ROWID; CREATE MATERIALIZED VIEW LOG ON times WITH ROWID; /*create materialized view join_sales_cust_time as fast refreshable at COMMIT time */ CREATE MATERIALIZED VIEW join_sales_cust_time REFRESH FAST ON COMMIT AS SELECT c.cust_id, c.cust_last_name, s.amount_sold, t.time_id, t.day_number_in_week, s.rowid srid, t.rowid trid, c.rowid crid FROM sales s, customers c, times t WHERE s.time_id = t.time_id AND s.cust_id = c.cust_id;
To create a nested materialized view on the table join_sales_cust_time, you would have to create a materialized view log on the table. Because this will be a single-table aggregate materialized view on join_sales_cust_time, you need to log all the necessary columns and use the INCLUDING NEW VALUES clause.
/* create materialized view log on join_sales_cust_time */ CREATE MATERIALIZED VIEW LOG ON join_sales_cust_time WITH ROWID (cust_name, day_number_in_week, amount_sold) INCLUDING NEW VALUES; /* create the single-table aggregate materialized view sum_sales_cust_time on
join_sales_cust_time as fast refreshable at COMMIT time */ CREATE MATERIALIZED VIEW sum_sales_cust_time REFRESH FAST ON COMMIT AS SELECT COUNT(*) cnt_all, SUM(amount_sold) sum_sales, COUNT(amount_sold) cnt_sales, cust_last_name, day_number_in_week FROM join_sales_cust_time GROUP BY cust_last_name, day_number_in_week;
This schema can be diagrammatically represented as in Figure 8-3.
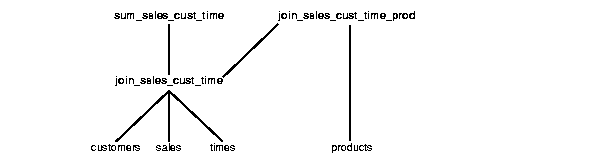
You can nest materialized views with joins and aggregates, but the ON DEMAND clause is necessary for FAST REFRESH.
Some types of nested materialized views cannot be fast refreshed. Use EXPLAIN_MVIEW to identify those types of materialized views. Because you have to invoke the refresh functions manually, ordering has to be taken into account. This is because the refresh for a materialized view that is built on other materialized views will use the current state of the other materialized views, whether they are fresh or not. You can find the dependent materialized views for a particular object using the PL/SQL function GET_MV_DEPENDENCIES in the DBMS_MVIEW package.
You should keep the following in mind when deciding whether to use nested materialized views:
The following restrictions exist on the way you can nest materialized views:
ON COMMIT is not supported for a higher-level materialized view that contains joins and aggregates.DBMS_MVIEW.REFRESH APIs will not automatically refresh nested materialized views unless explicitly specified. Thus, if monthly_sales_mv is based on sales_mv, you have to refresh sales_mv first, followed by monthly_sales_mv. Oracle does not automatically refresh monthly_sales_mv when you refresh sales_mv or vice versa.costs with a materialized view cost_mv based on it, you cannot then create a prebuilt materialized view on table costs. The result would make cost_mv a nested materialized view and this method of conversion is not supported.A materialized view can be created with the CREATE MATERIALIZED VIEW statement or using Oracle Enterprise Manager. Example 8-6 creates the materialized view cust_sales_mv.
CREATE MATERIALIZED VIEW cust_sales_mv PCTFREE 0 TABLESPACE demo STORAGE (INITIAL 16k NEXT 16k PCTINCREASE 0) PARALLEL BUILD IMMEDIATE REFRESH COMPLETE ENABLE QUERY REWRITE AS SELECT c.cust_last_name, SUM(amount_sold) AS sum_amount_sold FROM customers c, sales s WHERE s.cust_id = c.cust_id GROUP BY c.cust_last_name;
It is not uncommon in a data warehouse to have already created summary or aggregation tables, and you might not wish to repeat this work by building a new materialized view. In this case, the table that already exists in the database can be registered as a prebuilt materialized view. This technique is described in "Registering Existing Materialized Views".
Once you have selected the materialized views you want to create, follow these steps for each materialized view.
CREATE MATERIALIZED VIEW statement to create and, optionally, populate the materialized view. If a user-defined materialized view already exists, then use the ON PREBUILT TABLE clause in the CREATE MATERIALIZED VIEW statement. Otherwise, use the BUILD IMMEDIATE clause to populate the materialized view immediately, or the BUILD DEFERRED clause to populate the materialized view later. A BUILD DEFERRED materialized view is disabled for use by query rewrite until the first REFRESH, after which it will be automatically enabled, provided the ENABLE QUERY REWRITE clause has been specified.
| See Also:
Oracle9i SQL Reference for descriptions of the SQL statements |
The name of a materialized view must conform to standard Oracle naming conventions. However, if the materialized view is based on a user-defined prebuilt table, then the name of the materialized view must exactly match that table name.
If you already have a naming convention for tables and indexes, you might consider extending this naming scheme to the materialized views so that they are easily identifiable. For example, instead of naming the materialized view sum_of_sales, it could be called sum_of_sales_mv to denote that this is a materialized view and not a table or view.
Unless the materialized view is based on a user-defined prebuilt table, it requires and occupies storage space inside the database. Therefore, the storage needs for the materialized view should be specified in terms of the tablespace where it is to reside and the size of the extents.
If you do not know how much space the materialized view will require, then the DBMS_OLAP.ESTIMATE_SIZE package, which is described in Chapter 16, "Summary Advisor", can estimate the number of bytes required to store this uncompressed materialized view. This information can then assist the design team in determining the tablespace in which the materialized view should reside.
You should use data segment compression with highly redundant data, such as tables with many foreign keys. This is particularly useful for materialized views created with the ROLLUP clause. Data segment compression reduces disk use and memory use (specifically, the buffer cache), often leading to a better scaleup for read-only operations. Data segment compression can also speed up query execution.
| See Also:
Oracle9i SQL Reference for a complete description of |
Two build methods are available for creating the materialized view, as shown in Table 8-2. If you select BUILD IMMEDIATE, the materialized view definition is added to the schema objects in the data dictionary, and then the fact or detail tables are scanned according to the SELECT expression and the results are stored in the materialized view. Depending on the size of the tables to be scanned, this build process can take a considerable amount of time.
An alternative approach is to use the BUILD DEFERRED clause, which creates the materialized view without data, thereby enabling it to be populated at a later date using the DBMS_MVIEW.REFRESH package described in Chapter 14, "Maintaining the Data Warehouse".
| Build Method | Description |
|---|---|
|
|
Create the materialized view and then populate it with data |
|
|
Create the materialized view definition but do not populate it with data |
Before creating a materialized view, you can verify what types of query rewrite are possible by calling the procedure DBMS_MVIEW.EXPLAIN_MVIEW. Once the materialized view has been created, you can use DBMS_MVIEW.EXPLAIN_REWRITE to find out if (or why not) it will rewrite a specific query.
Even though a materialized view is defined, it will not automatically be used by the query rewrite facility. You must set the QUERY_REWRITE_ENABLED initialization parameter to TRUE before using query rewrite. You also must specify the ENABLE QUERY REWRITE clause if the materialized view is to be considered available for rewriting queries.
If this clause is omitted or specified as DISABLE QUERY REWRITE when the materialized view is created, the materialized view can subsequently be enabled for query rewrite with the ALTER MATERIALIZED VIEW statement.
If you define a materialized view as BUILD DEFERRED, it is not eligible for query rewrite until it is populated with data.
Query rewrite is not possible with all materialized views. If query rewrite is not occurring when expected, DBMS_MVIEW.EXPLAIN_REWRITE can help provide reasons why a specific query is not eligible for rewrite. Also, check to see if your materialized view satisfies all of the following conditions.
You should keep in mind the following restrictions:
ROWNUM, SYSDATE, non-repeatable PL/SQL functions, and so on).RAW or LONG RAW datatypes or object REFs.UNION, MINUS, and so on), rewrite will use them for full text match rewrite only.PREBUILT, the precision of the columns must agree with the precision of the corresponding SELECT expressions unless overridden by the WITH REDUCED PRECISION clause.You should keep in mind the following restrictions:
SYS.SELECT and GROUP BY lists, if present, must be the same in the query of the materialized view.AVG(AVG(x)) or AVG(x)+ AVG(x) are not allowed.CONNECT BY clauses are not allowed.When you define a materialized view, you can specify two refresh options: how to refresh and what type of refresh. If unspecified, the defaults are assumed as ON DEMAND and FORCE.
The two refresh execution modes are: ON COMMIT and ON DEMAND. Depending on the materialized view you create, some of the options may not be available. Table 8-3 describes the refresh modes.
When a materialized view is maintained using the ON COMMIT method, the time required to complete the commit may be slightly longer than usual. This is because the refresh operation is performed as part of the commit process. Therefore this method may not be suitable if many users are concurrently changing the tables upon which the materialized view is based.
If you anticipate performing insert, update or delete operations on tables referenced by a materialized view concurrently with the refresh of that materialized view, and that materialized view includes joins and aggregation, Oracle recommends you use ON COMMIT fast refresh rather than ON DEMAND fast refresh.
If you think the materialized view did not refresh, check the alert log or trace file.
If a materialized view fails during refresh at COMMIT time, you must explicitly invoke the refresh procedure using the DBMS_MVIEW package after addressing the errors specified in the trace files. Until this is done, the materialized view will no longer be refreshed automatically at commit time.
You can specify how you want your materialized views to be refreshed from the detail tables by selecting one of four options: COMPLETE, FAST, FORCE, and NEVER. Table 8-4 describes the refresh options.
Whether the fast refresh option is available depends upon the type of materialized view. You can call the procedure DBMS_MVIEW.EXPLAIN_MVIEW to determine whether fast refresh is possible.
The defining query of the materialized view is restricted as follows:
SYSDATE and ROWNUM.RAW or LONG RAW data types.Defining queries for materialized views with joins only and no aggregates have the following restrictions on fast refresh:
GROUP BY clauses or aggregates.WHERE clause of the query contains outer joins, then unique constraints must exist on the join columns of the inner join table.WHERE clause. However, if there are outer joins, the WHERE clause cannot have any selections. Furthermore, if there are outer joins, all the joins must be connected by ANDs and must use the equality (=) operator.FROM list must appear in the SELECT list of the query.FROM list of the query.Defining queries for materialized views with joins and aggregates have the following restrictions on fast refresh:
Fast refresh is supported for both ON COMMIT and ON DEMAND materialized views, however the following restrictions apply:
SUM, COUNT, AVG, STDDEV, VARIANCE, MIN and MAX are supported for fast refresh.COUNT(*) must be specified.AGG(expr), the corresponding COUNT(expr) must be present.VARIANCE(expr) or STDDEV(expr) is specified, COUNT(expr) and SUM(expr) must be specified. Oracle recommends that SUM(expr *expr) be specified. See Table 8-1 for further details.SELECT list must contain all GROUP BY columns.MIN or MAX aggregatesSUM(expr) but no COUNT(expr)COUNT(*)Such a materialized view is called an insert-only materialized view.
COMPATIBILITY parameter must be set to 9.0 if the materialized aggregate view has inline views, outer joins, self joins or grouping sets and FAST REFRESH is specified during creation. Note that all other requirements for fast refresh specified previously must also be satisfied.FROM clause can be fast refreshed provided the views can be completely merged. For information on which views will merge, refer to the Oracle9i Database Performance Tuning Guide and Reference.WHERE clause.ANDs and must use the equality (=) operator.CUBE, ROLLUP, Grouping Sets, or concatenation of them, the following restrictions apply:
SELECT list should contain grouping distinguisher that can either be a GROUPING_ID function on all GROUP BY expressions or GROUPING functions one for each GROUP BY expression. For example, if the GROUP BY clause of the materialized view is "GROUP BY CUBE(a, b)", then the SELECT list should contain either "GROUPING_ID(a, b)" or "GROUPING(a) AND GROUPING(b)" for the materialized view to be fast refreshable.GROUP BY should not result in any duplicate groupings. For example, "GROUP BY a, ROLLUP(a, b)" is not fast refreshable because it results in duplicate groupings "(a), (a, b), AND (a)".Materialized views with the UNION ALL set operator support the REFRESH FAST option if the following conditions are satisfied:
UNION ALL operator at the top level.
The UNION ALL operator cannot be embedded inside a subquery, with one exception: The UNION ALL can be in a subquery in the FROM clause provided the defining query is of the form SELECT * FROM (view or subquery with UNION ALL) as in the following example:
CREATE VIEW view_with_unionall_mv AS (SELECT c.rowid crid, c.cust_id, 2 umarker FROM customers c WHERE c.cust_last_name = 'Smith' UNION ALL SELECT c.rowid crid, c.cust_id, 3 umarker FROM customers c WHERE c.cust_last_name = 'Jones'); CREATE MATERIALIZED VIEW unionall_inside_view_mv REFRESH FAST ON DEMAND AS SELECT * FROM view_with_unionall;
Note that the view view_with_unionall_mv satisfies all requirements for fast refresh.
UNION ALL query must satisfy the requirements of a fast refreshable materialized view with aggregates or a fast refreshable materialized view with joins.
The appropriate materialized view logs must be created on the tables as required for the corresponding type of fast refreshable materialized view.
Note that Oracle also allows the special case of a single table materialized view with joins only provided the ROWID column has been included in the SELECT list and in the materialized view log. This is shown in the defining query of the view view_with_unionall_mv.
SELECT list of each query must include a maintenance column, called a UNION ALL marker. The UNION ALL column must have a distinct constant numeric or string value in each UNION ALL branch. Further, the marker column must appear in the same ordinal position in the SELECT list of each query block.UNION ALL.UNION ALL materialized views.UNION ALL.An ORDER BY clause is allowed in the CREATE MATERIALIZED VIEW statement. It is used only during the initial creation of the materialized view. It is not used during a full refresh or a fast refresh.
To improve the performance of queries against large materialized views, store the rows in the materialized view in the order specified in the ORDER BY clause. This initial ordering provides physical clustering of the data. If indexes are built on the columns by which the materialized view is ordered, accessing the rows of the materialized view using the index often reduces the time for disk I/O due to the physical clustering.
The ORDER BY clause is not considered part of the materialized view definition. As a result, there is no difference in the manner in which Oracle detects the various types of materialized views (for example, materialized join views with no aggregates). For the same reason, query rewrite is not affected by the ORDER BY clause. This feature is similar to the CREATE TABLE ... ORDER BY capability that exists in Oracle.
Materialized view logs are required if you want to use fast refresh. They are defined using a CREATE MATERIALIZED VIEW LOG statement on the base table that is to be changed. They are not created on the materialized view. For fast refresh of materialized views, the definition of the materialized view logs must specify the ROWID clause. In addition, for aggregate materialized views, it must also contain every column in the table referenced in the materialized view, the INCLUDING NEW VALUES clause and the SEQUENCE clause.
An example of a materialized view log is shown as follows where one is created on the table sales.
CREATE MATERIALIZED VIEW LOG ON sales WITH ROWID (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold) INCLUDING NEW VALUES;
Oracle recommends that the keyword SEQUENCE be included in your materialized view log statement unless you are sure that you will never perform a mixed DML operation (a combination of INSERT, UPDATE, or DELETE operations on multiple tables).
The boundary of a mixed DML operation is determined by whether the materialized view is ON COMMIT or ON DEMAND.
ON COMMIT, the mixed DML statements occur within the same transaction because the refresh of the materialized view will occur upon commit of this transaction.ON DEMAND, the mixed DML statements occur between refreshes. The following example of a materialized view log illustrates where one is created on the table sales that includes the SEQUENCE keyword:
CREATE MATERIALIZED VIEW LOG ON sales WITH SEQUENCE, ROWID (prod_id, cust_id, time_id, channel_id, promo_id, quantity_sold, amount_sold) INCLUDING NEW VALUES;
A materialized view can also be created using Oracle Enterprise Manager by selecting the materialized view object type. There is no difference in the information required if this approach is used. However, you must complete three property sheets and you must ensure that the option Enable Query Rewrite on the General sheet is selected.
| See Also:
Oracle Enterprise Manager Configuration Guide and Chapter 16, "Summary Advisor" for further information |
When using certain materialized views, you must ensure that your NLS parameters are the same as when you created the materialized view. Materialized views with this restriction are as follows:
SELECT list of a materialized view, or inside an aggregate of a materialized aggregate view. This restriction does not apply to expressions that involve only numeric data, for example, a+b where a and b are numeric fields.Some data warehouses have implemented materialized views in ordinary user tables. Although this solution provides the performance benefits of materialized views, it does not:
Because of these limitations, and because existing materialized views can be extremely large and expensive to rebuild, you should register your existing materialized view tables with Oracle whenever possible. You can register a user-defined materialized view with the CREATE MATERIALIZED VIEW ... ON PREBUILT TABLE statement. Once registered, the materialized view can be used for query rewrites or maintained by one of the refresh methods, or both.
The contents of the table must reflect the materialization of the defining query at the time you register it as a materialized view, and each column in the defining query must correspond to a column in the table that has a matching datatype. However, you can specify WITH REDUCED PRECISION to allow the precision of columns in the defining query to be different from that of the table columns.
The table and the materialized view must have the same name, but the table retains its identity as a table and can contain columns that are not referenced in the defining query of the materialized view. These extra columns are known as unmanaged columns. If rows are inserted during a refresh operation, each unmanaged column of the row is set to its default value. Therefore, the unmanaged columns cannot have NOT NULL constraints unless they also have default values.
Materialized views based on prebuilt tables are eligible for selection by query rewrite provided the parameter QUERY_REWRITE_INTEGRITY is set to at least the level of stale_tolerated or trusted.
| See Also:
Chapter 22, "Query Rewrite" for details about integrity levels |
When you drop a materialized view that was created on a prebuilt table, the table still exists--only the materialized view is dropped.
When a prebuilt table is registered as a materialized view and query rewrite is desired, the parameter QUERY_REWRITE_INTEGRITY must be set to at least stale_tolerated because, when it is created, the materialized view is marked as unknown. Therefore, only stale integrity modes can be used.
The following example illustrates the two steps required to register a user-defined table. First, the table is created, then the materialized view is defined using exactly the same name as the table. This materialized view sum_sales_tab is eligible for use in query rewrite.
CREATE TABLE sum_sales_tab PCTFREE 0 TABLESPACE demo STORAGE (INITIAL 16k NEXT 16k PCTINCREASE 0) AS SELECT s.prod_id, SUM(amount_sold) AS dollar_sales, SUM(quantity_sold) AS unit_sales FROM sales s GROUP BY s.prod_id; CREATE MATERIALIZED VIEW sum_sales_tab ON PREBUILT TABLE WITHOUT REDUCED PRECISION ENABLE QUERY REWRITE AS SELECT s.prod_id, SUM(amount_sold) AS dollar_sales, SUM(quantity_sold) AS unit_sales FROM sales s GROUP BY s.prod_id;
You could have compressed this table to save space. See "Storage And Data Segment Compression" for details regarding data segment compression.
In some cases, user-defined materialized views are refreshed on a schedule that is longer than the update cycle. For example, a monthly materialized view might be updated only at the end of each month, and the materialized view values always refer to complete time periods. Reports written directly against these materialized views implicitly select only data that is not in the current (incomplete) time period. If a user-defined materialized view already contains a time dimension:
If the user-defined materialized view does not contain a time dimension, then:
Because of the large volume of data held in a data warehouse, partitioning is an extremely useful option when designing a database.
Partitioning the fact tables improves scalability, simplifies system administration, and makes it possible to define local indexes that can be efficiently rebuilt. Partitioning the fact tables also improves the opportunity of fast refreshing the materialized view when the partition maintenance operation occurs.
Partitioning a materialized view also has benefits for refresh, because the refresh procedure can use parallel DML to maintain the materialized view.
| See Also:
Chapter 5, "Parallelism and Partitioning in Data Warehouses" for further details about partitioning |
It is possible and advantageous to track freshness to a finer grain than the entire materialized view. The ability to identify which rows in a materialized view are affected by a certain detail table partition, is known as Partition Change Tracking (PCT). When one or more of the detail tables are partitioned, it may be possible to identify the specific rows in the materialized view that correspond to a modified detail partition(s); those rows become stale when a partition is modified while all other rows remain fresh.
Partition Change Tracking can be used to identify which materialized view rows correspond to a particular detail table. Partition Change Tracking is also used to support fast refresh after partition maintenance operations on detail tables. For instance, if a detail table partition is truncated or dropped, the affected rows in the materialized view are identified and deleted. Identifying which materialized view rows are fresh or stale, rather than considering the entire materialized view as stale, allows query rewrite to use those rows that are fresh while in QUERY_REWRITE_INTEGRITY=ENFORCED or TRUSTED modes.
To support PCT, a materialized view must satisfy the following requirements:
DBMS_MVIEW.PMARKER function.GROUP BY clause, the partition key column or the partition marker must be present in the GROUP BY clause.COMPATIBILITY initialization parameter must be a minimum of 9.0.0.0.0.UNION ALL materialized views.Partition change tracking requires sufficient information in the materialized view to be able to correlate each materialized view row back to its corresponding detail row in the source partitioned detail table. This can be accomplished by including the detail table partition key columns in the select list and, if GROUP BY is used, in the GROUP BY list. Depending on the desired level of aggregation and the distinct cardinalities of the partition key columns, this has the unfortunate effect of significantly increasing the cardinality of the materialized view. For example, say a popular metric is the revenue generated by a product during a given year. If the sales table were partitioned by time_id, it would be a required field in the SELECT clause and the GROUP BY clause of the materialized view. If there were 1000 different products sold each day, it would substantially increase the number of rows in the materialized view.
In many cases, the advantages of PCT will be offset by this restriction for highly aggregated materialized views. The DBMS_MVIEW.PMARKER function is designed to significantly reduce the cardinality of the materialized view (see Example 8-7 for an example). The function returns a partition identifier that uniquely identifies the partition for a specified row within a specified partition table. The DBMS_MVIEW.PMARKER function is used instead of the partition key column in the SELECT and GROUP BY clauses.
Unlike the general case of a PL/SQL function in a materialized view, use of the DBMS_MVIEW.PMARKER does not prevent rewrite with that materialized view even when the rewrite mode is QUERY_REWRITE_INTEGRITY=enforced.
The following example uses the sh sample schema and the three detail tables sales, products, and times to create two materialized views. For this example, sales is a partitioned table using the time_id column and products is partitioned by the prod_category column. times is not a partitioned table.
The first materialized view is for the yearly sales revenue for each product.
The second materialized view is for monthly customer sales. As customers tend to purchase in bulk, sales average just two orders for each customer per month. Therefore, the impact of including the time_id in the materialized view will not unacceptably increase the number of rows stored. However, most orders are large and contain many different products. With approximately 1000 different products sold each day, including the time_id in the materialized view would substantially increase the cardinality. This materialized view uses the DBMS_MVIEW.PMARKER function.
The detail tables must have materialized view logs for FAST REFRESH.
CREATE MATERIALIZED VIEW LOG ON SALES WITH ROWID (prod_id, time_id, quantity_sold, amount_sold) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON PRODUCTS WITH ROWID (prod_id, prod_name, prod_desc) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW LOG ON TIMES WITH ROWID (time_id, calendar_month_name, calendar_year) INCLUDING NEW VALUES; CREATE MATERIALIZED VIEW cust_mth_sales_mv BUILD DEFERRED REFRESH FAST ON DEMAND ENABLE QUERY REWRITE AS SELECT s.time_id, p.prod_id, SUM(s.quantity_sold), SUM(s.amount_sold), p.prod_name, t.calendar_month_name, COUNT(*), COUNT(s.quantity_sold), COUNT(s.amount_sold) FROM sales s, products p, times t WHERE s.time_id = t.time_id AND s.prod_id = p.prod_id GROUP BY t.calendar_month_name, p.prod_id, p.prod_name, s.time_id;
cust_mth_sales_mv includes the partition key column from table sales (time_id) in both its SELECT and GROUP BY lists. This enables PCT on table sales for materialized view cust_mth_sales_mv. However, the GROUP BY and SELECT lists include PRODUCTS.PROD_ID rather than the partition key column (PROD_CATEGORY) of the products table. Therefore, PCT is not enabled on table products for this materialized view. In other words, any partition maintenance operation to the sales table will allow a PCT fast refresh of cust_mth_sales_mv. However, PCT fast refresh is not possible after any kind of modification to the products table. To correct this, the GROUP BY and SELECT lists must include column PRODUCTS.PROD_CATEGORY. Following a partition maintenance operation, such as a drop partition, a PCT fast refresh should be performed on any materialized view that is referencing the table upon which the partition operations are undertaken.
CREATE MATERIALIZED VIEW prod_yr_sales_mv BUILD DEFERRED REFRESH FAST ON DEMAND ENABLE QUERY REWRITE AS SELECT DBMS_MVIEW.PMARKER(s.rowid), DBMS_MVIEW.PMARKER(p.rowid), s.prod_id, SUM(s.amount_sold), SUM(s.quantity_sold), p.prod_name, t.calendar_year, COUNT(*), COUNT(s.amount_sold), COUNT(s.quantity_sold) FROM sales s, products p, times t WHERE s.time_id = t.time_id AND s.prod_id = p.prod_id GROUP BY DBMS_MVIEW.PMARKER (s.rowid), DBMS_MVIEW.PMARKER (p.rowid), t.calendar_year, s.prod_id, p.prod_name;
prod_yr_sales_mv includes the DBMS_MVIEW.PMARKER function on the sales and products tables in both its SELECT and GROUP BY lists. This enables partition change tracking on both the sales table and the products table with significantly less cardinality impact than grouping by the respective partition key columns. In this example, the desired level of aggregation for the prod_yr_sales_mv is to group by times.calendar_year. Using the DBMS_MVIEW.PMARKER function, the materialized view cardinality is increased only by a factor of the number of partitions in the sales table times, the number of partitions in the products table. This would generally be significantly less than the cardinality impact of including the respective partition key columns.
A subsequent INSERT statement adds a new row to the sales_part3 partition of table sales. At this point, because cust_mth_sales_mv and prod_yr_sales_mv have partition change tracking available on table sales, Oracle can determine that those rows in these materialized views corresponding to sales_part3 are stale, while all other rows in these materialized views are unchanged in their freshness state. An INSERT INTO products statement is not tracked for materialized view cust_mth_sales_mv. Therefore, cust_mth_sales_mv becomes completely stale when the products table is modified in this way.
Partitioning a materialized view involves defining the materialized view with the standard Oracle partitioning clauses, as illustrated in the following example. This statement creates a materialized view called part_sales_mv, which uses three partitions, can be fast refreshed, and is eligible for query rewrite.
CREATE MATERIALIZED VIEW part_sales_mv PARALLEL PARTITION BY RANGE (time_id) (PARTITION month1 VALUES LESS THAN (TO_DATE('31-12-1998', 'DD-MM-YYYY')) PCTFREE 0 PCTUSED 99 STORAGE (INITIAL 64k NEXT 16k PCTINCREASE 0) TABLESPACE sf1, PARTITION month2 VALUES LESS THAN (TO_DATE('31-12-1999', 'DD-MM-YYYY')) PCTFREE 0 PCTUSED 99 STORAGE (INITIAL 64k NEXT 16k PCTINCREASE 0) TABLESPACE sf2, PARTITION month3 VALUES LESS THAN (TO_DATE('31-12-2000', 'DD-MM-YYYY')) PCTFREE 0 PCTUSED 99 STORAGE (INITIAL 64k NEXT 16k PCTINCREASE 0) TABLESPACE sf3) BUILD DEFERRED REFRESH FAST ENABLE QUERY REWRITE AS SELECT s.cust_id, s.time_id, SUM(s.amount_sold) AS sum_dol_sales, SUM(s.quantity_sold) AS sum_unit_sales FROM sales s GROUP BY s.time_id, s.cust_id;
Alternatively, a materialized view can be registered to a partitioned prebuilt table as illustrated in the following example:
CREATE TABLE part_sales_tab(time_id, cust_id, sum_dollar_sales, sum_unit_sale) PARALLEL PARTITION BY RANGE (time_id) ( PARTITION month1 VALUES LESS THAN (TO_DATE('31-12-1998', 'DD-MM-YYYY')) PCTFREE 0 PCTUSED 99 STORAGE (INITITAL 64k NEXT 16k PCTINCREASE 0) TABLESPACE sf1, PARTITION month2 VALUES LESS THAN (TO_DATE('31-12-1999', 'DD-MM-YYYY')) PCTFREE 0 PCTUSED 99 STORAGE (INITIAL 64k NEXT 16k PCTINCREASE 0) TABLESPACE sf2, PARTITION month3 VALUES LESS THAN (TO_DATE('31-12-2000', 'DD-MM-YYYY')) PCTFREE 0 PCTUSED 99 STORAGE (INITIAL 64k NEXT 16k PCTINCREASE 0) TABLESPACE sf3) AS SELECT s.time_key, s.cust_id, SUM(s.amount_sold) AS sum_dollar_sales, SUM(s.quantity_sold) AS sum_unit_sales FROM sales s GROUP BY s.time_id, s.cust_id; CREATE MATERIALIZED VIEW part_sales_tab_mv ON PREBUILT TABLE ENABLE QUERY REWRITE AS SELECT s.time_id, s.cust_id, SUM(s.amount_sold) AS sum_dollar_sales, SUM(s.quantity_sold) AS sum_unit_sales FROM sales s GROUP BY s.time_id, s.cust_id;
In this example, the table part_sales_tab has been partitioned over three months and then the materialized view was registered to use the prebuilt table. This materialized view is eligible for query rewrite because the ENABLE QUERY REWRITE clause has been included.
When a data warehouse or data mart contains a time dimension, it is often desirable to archive the oldest information and then reuse the storage for new information. This is called the rolling window scenario. If the fact tables or materialized views include a time dimension and are horizontally partitioned by the time attribute, then management of rolling materialized views can be reduced to a few fast partition maintenance operations provided the unit of data that is rolled out equals, or is at least aligned with, the range partitions.
If you plan to have rolling materialized views in your warehouse, you should determine how frequently you plan to perform partition maintenance operations, and you should plan to partition fact tables and materialized views to reduce the amount of system administration overhead required when old data is aged out. An additional consideration is that you might want to use data compression on your infrequently updated partitions.
You are not restricted to using range partitions. For example, a composite partition using both a time value and a key value could result in a good partition solution for your data.
| See Also:
Chapter 14, "Maintaining the Data Warehouse" for further details regarding |
This section discusses certain OLAP concepts and how relational databases can handle OLAP queries. Next, it recommends an approach for using materialized views to meet OLAP performance needs. Finally, it discusses using materialized views with set operators, a common scenario for OLAP environments.
While data warehouse environments typically view data in the form of a star schema, OLAP environments view data in the form of a hierarchical cube. A hierarchical cube includes both detail data and aggregated data: it is a data set where the data is aggregated along the rollup hierarchy of each of its dimensions and these aggregations are combined across dimensions. It includes the typical set of aggregations needed for business intelligence queries.
Consider a sales data set with two dimensions, each of which has a 4-level hierarchy:
This means there are 16 aggregate groups in the hierarchical cube. This is because the four levels of time are multiplied by four levels of product to produce the cube. Table 8-5 shows the four levels of each dimension.
| ROLLUP By Time | ROLLUP By Product |
|---|---|
|
year, quarter, month |
division, brand, item |
|
year, quarter |
division, brand |
|
year |
division |
|
all times |
all products |
Note that as you increase the number of dimensions and levels, the number of groups to calculate increases dramatically. This example involves 16 groups, but if you were to add just two more dimensions with the same number of levels, you would have 4 x 4 x 4 x 4 = 256 different groups. Also, consider that a similar increase in groups occurs if you have multiple hierarchies in your dimensions. For example, the time dimension might have an additional hierarchy of fiscal month rolling up to fiscal quarter and then fiscal year. Handling the explosion of groups has historically been the major challenge in data storage for OLAP systems.
Typical OLAP queries slice and dice different parts of the cube comparing aggregations from one level to aggregation from another level. For instance, a query might find sales of the grocery division for the month of January, 2002 and compare them with total sales of the grocery division for all of 2001.
Oracle9i can specify hierarchical cubes in a simple and efficient SQL query. These hierarchical cubes represent the logical cubes referred to in many OLAP products. To specify data in the form of hierarchical cubes, users can work with the extensions to GROUP BY clause introduced in Oracle9i.
You can use one of Oracle's new extensions to the GROUP BY clause, concatenated grouping sets, to generate the aggregates needed for a hierarchical cube of data. By using concatenated rollup (rolling up along the hierarchy of each dimension and then concatenate them across multiple dimensions), you can generate all the aggregations needed by a hierarchical cube. These extensions are discussed in detail in Chapter 18, "SQL for Aggregation in Data Warehouses".
The following shows the GROUP BY clause needed to create a hierarchical cube for the 2-dimension example described earlier. The following simple syntax performs a concatenated rollup:
GROUP BY ROLLUP(year, quarter, month), ROLLUP(Division, brand, item);
This concatenated rollup takes the ROLLUP aggregations listed in the table of the prior section and perform a cross-product on them. The cross-product will create the 16 (4x4) aggregate groups needed for a hierarchical cube of the data.
Analytic applications treat data as cubes, but they want only certain slices and regions of the cube. Concatenated rollup (hierarchical cube) enables relational data to be treated as cubes. To handle complex analytic queries, the fundamental technique is to enclose a hierarchical cube query in an outer query that specifies the exact slice needed from the cube. Oracle9i optimizes the processing of hierarchical cubes nested inside slicing queries. By applying many powerful algorithms, these queries can be processed at unprecedented speed and scale. This enables OLAP tools and analytic applications to use a consistent style of queries to handle the most complex questions.
Consider the following analytic query. It consists of a hierarchical cube query nested in a slicing query.
SELECT month, division, sum_sales FROM (SELECT year, quarter, month, division, brand, item, SUM(sales) sum_sales, GROUPING_ID(grouping-columns) gid FROM sales, products, time WHERE join-condition GROUP BY ROLLUP(year, quarter, month), ROLLUP(division, brand, item) ) WHERE division = 25 AND month = 200201 AND gid = gid-for-Division-Month;
The inner hierarchical cube specified defines a simple cube, with two dimensions and four levels in each dimension. It would generate 16 groups (4 Time levels * 4 Product levels). The GROUPING_ID function in the query identifies the specific group each row belongs to, based on the aggregation level of the grouping-columns in its argument.
The outer query applies the constraints needed for our specific query, limiting Division to a value of 25 and Month to a value of 200201 (representing January 2002 in this case). In conceptual terms, it slices a small chunk of data from the cube. The outer query's constraint on the GID column, indicated in the query by gid-for-division-month would be the value of a key indicating that the data is grouped as a combination of division and month. The GID constraint selects only those rows that are aggregated at the level of a GROUP BY month, division clause.
Oracle removes unneeded aggregation groups from query processing based on the outer query conditions. The outer conditions of the previous query limit the result set to a single group aggregating division and month. Any other groups involving year, month, brand, and item are unnecessary here. The group pruning optimization recognizes this and transforms the query into:
SELECT month, division, sum_sales FROM (SELECT null, null, month, division, null, null, SUM(sales) sum_sales, GROUPING_ID(grouping-columns) gid FROM sales, products, time WHERE join-condition GROUP BY month, division) WHERE division = 25 AND month = 200201 AND gid = gid-for-Division-Month;
The bold items highlight the changed SQL. The inner query now has a simple GROUP BY clause of month, division. The columns year, quarter, brand and item have been converted to null to match the simplified GROUP BY clause. Because the query now requests just one group, fifteen out of sixteen groups are removed from the processing, greatly reducing the work. For a cube with more dimensions and more levels, the savings possible through group pruning can be far greater. Note that the group pruning transformation works with all the GROUP BY extensions: ROLLUP, CUBE, and GROUPING SETS.
While the Oracle optimizer has simplified the previous query to a simple GROUP BY, faster response times can be achieved if the group is precomputed and stored in a materialized view. Because OLAP queries can ask for any slice of the cube many groups may need to be precomputed and stored in a materialized view. This is discussed in the next section.
OLAP requires fast response times for multiple users, and this in turn demands that significant parts of an OLAP cube be precomputed and held in materialized views. Oracle9i enables great flexibility in the use of materialized views for OLAP.
Data warehouse designers can choose exactly how much data to materialize. A data warehouse can have the full OLAP cube materialized. While this will take the most storage space, it ensures quick response for any query within the cube. On the other hand, a warehouse could have just partial materialization, saving storage space, but allowing only a subset of possible queries to be answered at highest speed. If an OLAP environment's queries cover the full range of aggregate groupings possible in its data set, it may be best to materialize the whole hierarchical cube.
This means that each dimension's aggregation hierarchy is precomputed in combination with each of the other dimensions. Naturally, precomputing a full hierarchical cube requires more disk space and higher creation and refresh times than a small set of aggregate groups. The trade-off in processing time and disk space versus query performance needs to be considered before deciding to create it. An additional possibility you could consider is to use data compression to lessen your disk space requirements.
| See Also:
Oracle9i SQL Reference for data compression syntax and restrictions and "Storage And Data Segment Compression" for details regarding compression |
This section shows complete and partial hierarchical cube materialized views.
CREATE MATERIALIZED VIEW sales_hierarchical_cube_mv REFRESH FAST ON DEMAND ENABLE QUERY REWRITE AS SELECT country_id, cust_state_province, cust_city, prod_category, prod_subcategory, prod_name, calendar_month_number, day_number_in_month, day_number_in_week, GROUPING_ID(country_id, cust_state_province, cust_city, prod_category, prod_subcategory, prod_name, calendar_month_number, day_number_in_month, day_number_in_week) gid, SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star FROM sales s, products p, customers c, times t WHERE s.cust_id = c.cust_id AND s.prod_id = p.prod_id AND s.time_id = t.time_id GROUP BY ROLLUP(country_id, (cust_state_province, cust_city)), ROLLUP(prod_category, (prod_subcategory, prod_name)), ROLLUP(calendar_month_number, (day_number_in_month, day_number_in_week)) PARTITION BY LIST (gid) ...;
This creates a complete hierarchical cube stored in a list-partitioned materialized view.
CREATE MATERIALIZED VIEW sales_mv REFRESH FAST ON DEMAND ENABLE QUERY REWRITE AS SELECT country_id, cust_state_province, cust_city, prod_category, prod_subcategory, prod_name, GROUPING_ID(country_id, cust_state_province, cust_city, prod_category, prod_subcategory, prod_name) gid, SUM(amount_sold) s_sales, COUNT(amount_sold) c_sales, COUNT(*) c_star FROM sales s, products p, customers c WHERE s.cust_id = c.cust_id and s.prod_id = p.prod_id GROUP BY GROUPING SETS ((country_id, cust_state_province, cust_city), (country_id, prod_category, prod_subcategory, prod_name), (prod_category, prod_subcategory, prod_name),(country_id, prod_category)) PARTITION BY LIST (gid) ...;
This creates a partial hierarchical cube stored in a list-partitioned materialized view. Note that it explicitly lists the groups needed using the GROUPING SETS extension to GROUP BY.
Materialized views with multiple aggregate groups will give their best performance when partitioned appropriately. The most effective partitioning scheme for these materialized views is to use list partitioning, especially with the GROUPING_ID column. By partitioning the materialized views this way, you enable partition pruning for queries rewritten against this materialized view: only relevant aggregate groups will be accessed, greatly reducing the query processing cost.
You should consider data compression when using highly redundant data, such as tables with many foreign keys. In particular, materialized views created with the ROLLUP clause are likely candidates.
| See Also:
Oracle9i SQL Reference for data compression syntax and restrictions and "Storage And Data Segment Compression" for details regarding compression |
Oracle provides some support for materialized views whose defining query involves set operators. Materialized views with set operators can now be created enabled for query rewrite. Query rewrite with such materialized views is supported using full exact text match. You can refresh the materialized view using either ON COMMIT or ON DEMAND refresh.
Fast refresh is supported if the defining query has the UNION ALL operator at the top level and each query block in the UNION ALL, meets the requirements of a materialized view with aggregates or materialized view with joins only. Further, the materialized view must include a constant column (known as a UNION ALL marker) that has a distinct value in each query block, which, in the following example, is columns 1 marker and 2 marker.
See "Restrictions on Fast Refresh on Materialized Views With the UNION ALL Operator" for detailed restrictions on fast refresh for materialized views with UNION ALL.
The following examples illustrate creation of fast refreshable materialized views involving UNION ALL.
To create a UNION ALL materialized view with two join views, the materialized view logs must have the rowid column and, in the following example, the UNION ALL marker is the columns, 1 marker and 2 marker.
CREATE MATERIALIZED VIEW LOG ON sales WITH ROWID; CREATE MATERIALIZED VIEW LOG ON customers WITH ROWID; CREATE MATERIALIZED VIEW unionall_sales_cust_joins_mv BUILD DEFERRED REFRESH FAST ON COMMIT ENABLE QUERY REWRITE AS (SELECT c.rowid crid, s.rowid srid, c.cust_id, s.amount_sold, 1 marker FROM sales s, customers c WHERE s.cust_id = c.cust_id AND c.cust_last_name = 'Smith') UNION ALL (SELECT c.rowid crid, s.rowid srid, c.cust_id, s.amount_sold, 2 marker FROM sales s, customers c WHERE s.cust_id = c.cust_id AND c.cust_last_name = 'Brown');
The following example shows a UNION ALL of a materialized view with joins and a materialized view with aggregates. A couple of things can be noted in this example. Nulls or constants can be used to ensure that the data types of the corresponding SELECT list columns match. Also the UNION ALL marker column can be a string literal, which is 'Year' umarker, 'Quarter' umarker, or 'Daily' umarker in the following example:
DROP MATERIALIZED VIEW LOG ON sales; CREATE MATERIALIZED VIEW LOG ON sales WITH ROWID, SEQUENCE (amount_sold, time_id) INCLUDING NEW VALUES; DROP MATERIALIZED VIEW LOG ON times; CREATE MATERIALIZED VIEW LOG ON times WITH ROWID, SEQUENCE (time_id, fiscal_year, fiscal_quarter_number, day_number_in_week) INCLUDING NEW VALUES; DROP MATERIALIZED VIEW unionall_sales_mix_mv; CREATE MATERIALIZED VIEW unionall_sales_mix_mv BUILD DEFERRED REFRESH FAST ON DEMAND AS (SELECT 'Year' umarker, NULL, NULL, t.fiscal_year, SUM(s.amount_sold) amt, COUNT(s.amount_sold), COUNT(*) FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.fiscal_year) UNION ALL (SELECT 'Quarter' umarker, NULL, NULL, t.fiscal_quarter_number, SUM(s.amount_sold) amt, COUNT(s.amount_sold), COUNT(*) FROM sales s, times t WHERE s.time_id = t.time_id and t.fiscal_year = 2001 GROUP BY t.fiscal_quarter_number) UNION ALL (SELECT 'Daily' umarker, s.rowid rid, t.rowid rid2, t.day_number_in_week, s.amount_sold amt, 1, 1 FROM sales s, times t WHERE s.time_id = t.time_id and t.time_id between '01-Jan-01' and '01-Dec-31');
The two most common operations on a materialized view are query execution and fast refresh, and each operation has different performance requirements. Query execution might need to access any subset of the materialized view key columns, and might need to join and aggregate over a subset of those columns. Consequently, query execution usually performs best if a single-column bitmap index is defined on each materialized view key column.
In the case of materialized views containing only joins using fast refresh, Oracle recommends that indexes be created on the columns that contain the rowids to improve the performance of the refresh operation.
If a materialized view using aggregates is fast refreshable, then an index is automatically created unless USING NO INDEX is specified in the CREATE MATERIALIZED VIEW statement.
| See Also:
Chapter 21, "Using Parallel Execution" for further details |
Dependencies related to materialized views are automatically maintained to ensure correct operation. When a materialized view is created, the materialized view depends on the detail tables referenced in its definition. Any DML operation, such as a INSERT, or DELETE, UPDATE, or DDL operation on any dependency in the materialized view will cause it to become invalid. To revalidate a materialized view, use the ALTER MATERIALIZED VIEW COMPILE statement.
A materialized view is automatically revalidated when it is referenced. In many cases, the materialized view will be successfully and transparently revalidated. However, if a column has been dropped in a table referenced by a materialized view or the owner of the materialized view did not have one of the query rewrite privileges and that privilege has now been granted to the owner, you should use the following statement to revalidate the materialized view:
ALTER MATERIALIZED VIEW mview_name ENABLE QUERY REWRITE;
The state of a materialized view can be checked by querying the data dictionary views USER_MVIEWS or ALL_MVIEWS. The column STALENESS will show one of the values FRESH, STALE, UNUSABLE, UNKNOWN, or UNDEFINED to indicate whether the materialized view can be used. The state is maintained automatically, but it can be manually updated by issuing an ALTER MATERIALIZED VIEW name COMPILE statement.
To create a materialized view in your own schema, you must have the CREATE MATERIALIZED VIEW privilege and the SELECT privilege to any tables referenced that are in another schema. To create a materialized view in another schema, you must have the CREATE ANY MATERIALIZED VIEW privilege and the owner of the materialized view needs SELECT privileges to the tables referenced if they are from another schema.
Moreover, if you enable query rewrite on a materialized view that references tables outside your schema, you must have the GLOBAL QUERY REWRITE privilege or the QUERY REWRITE object privilege on each table outside your schema.
If the materialized view is on a prebuilt container, the creator, if different from the owner, must have SELECT WITH GRANT privilege on the container table.
If you continue to get a privilege error while trying to create a materialized view and you believe that all the required privileges have been granted, then the problem is most likely due to a privilege not being granted explicitly and trying to inherit the privilege from a role instead. The owner of the materialized view must have explicitly been granted SELECT access to the referenced tables if the tables are in a different schema.
If the materialized view is being created with ON COMMIT REFRESH specified, then the owner of the materialized view requires an additional privilege if any of the tables in the defining query are outside the owner's schema. In that case, the owner requires the ON COMMIT REFRESH system privilege or the ON COMMIT REFRESH object privilege on each table outside the owner's schema.
Five modifications can be made to a materialized view. You can:
FAST/FORCE/COMPLETE/NEVER)ON COMMIT/ON DEMAND)All other changes are achieved by dropping and then re-creating the materialized view.
The COMPILE clause of the ALTER MATERIALIZED VIEW statement can be used when the materialized view has been invalidated. This compile process is quick, and allows the materialized view to be used by query rewrite again.
| See Also:
Oracle9i SQL Reference for further information about the |
Use the DROP MATERIALIZED VIEW statement to drop a materialized view. For example:
DROP MATERIALIZED VIEW sales_sum_mv;
This statement drops the materialized view sales_sum_mv. If the materialized view was prebuilt on a table, then the table is not dropped, but it can no longer be maintained with the refresh mechanism or used by query rewrite. Alternatively, you can drop a materialized view using Oracle Enterprise Manager.
You can use the DBMS_MVIEW.EXPLAIN_MVIEW procedure to learn what is possible with a materialized view or potential materialized view. In particular, this procedure enables you to determine:
Using this procedure is straightforward. You simply call DBMS_MVIEW.EXPLAIN_MVIEW, passing in as a single parameter the schema and materialized view name for an existing materialized view. Alternatively, you can specify the SELECT string for a potential materialized view. The materialized view or potential materialized view is then analyzed and the results are written into either a table called MV_CAPABILITIES_TABLE, which is the default, or to an array called MSG_ARRAY.
Note that you must run the utlxmv.sql script prior to calling EXPLAIN_MVIEW except when you are placing the results in MSG_ARRAY. The script is found in the admin directory. In addition, you must create MV_CAPABILITIES_TABLE in the current schema. An explanation of the various capabilities is in Table 8-6, and all the possible messages are listed in Table 8-7.
The DBMS_MVIEW.EXPLAIN_MVIEW procedure has the following parameters:
stmt_id
An optional parameter. A client-supplied unique identifier to associate output rows with specific invocations of EXPLAIN_MVIEW.
mv
The name of an existing materialized view or the query definition of a potential materialized view you want to analyze.
msg-array
The PL/SQL varray that receives the output.
DBMS_MVIEW.EXPLAIN_MVIEW analyzes the specified materialized view in terms of its refresh and rewrite capabilities and inserts its results (in the form of multiple rows) into MV_CAPABILITIES_TABLE or MSG_ARRAY.
| See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for further information about the |
The following PL/SQL declarations that are made for you in the DBMS_MVIEW package show the order and datatypes of these parameters for explaining an existing materialized view and a potential materialized view with output to a table and to a VARRAY.
Explain an existing or potential materialized view with output to MV_CAPABILITIES_TABLE:
DBMS_MVIEW.EXPLAIN_MVIEW (mv IN VARCHAR2, stmt_id IN VARCHAR2:= NULL);
Explain an existing or potential materialized view with output to a VARRAY:
DBMS_MVIEW.EXPLAIN_MVIEW (mv IN VARCHAR2, msg_array OUT SYS.ExplainMVArrayType);
One of the simplest ways to use DBMS_MVIEW.EXPLAIN_MVIEW is with the MV_CAPABILITIES_TABLE, which has the following structure:
CREATE TABLE MV_CAPABILITIES_TABLE ( STMT_ID VARCHAR(30), -- client-supplied unique statement identifier MV VARCHAR(30), -- NULL for SELECT based EXPLAIN_MVIEW CAPABILITY_NAME VARCHAR(30), -- A descriptive name of particular -- capabilities, such as REWRITE. -- See Table 8-6 POSSIBLE CHARACTER(1), -- Y = capability is possible -- N = capability is not possible RELATED_TEXT VARCHAR(2000), -- owner.table.column, and so on related to -- this message RELATED_NUM NUMBER, -- When there is a numeric value -- associated with a row, it goes here. MSGNO INTEGER, -- When available, message # explaining -- why disabled or more details when -- enabled. MSGTXT VARCHAR(2000), -- Text associated with MSGNO SEQ NUMBER); -- Useful in ORDER BY clause when -- selecting from this table.
You can use the utlxmv.sql script found in the admin directory to create MV_CAPABILITIES_TABLE.
First, create the materialized view. Alternatively, you can use EXPLAIN_MVIEW on a potential materialized view using its SELECT statement.
CREATE MATERIALIZED VIEW cal_month_sales_mv BUILD IMMEDIATE REFRESH FORCE ENABLE QUERY REWRITE AS SELECT t.calendar_month_desc, SUM(s.amount_sold) AS dollars FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;
Then, you invoke EXPLAIN_MVIEW with the materialized view to explain. You need to use the SEQ column in an ORDER BY clause so the rows will display in a logical order. If a capability is not possible, N will appear in the P column and an explanation in the MSGTXT column. If a capability is not possible for more than one reason, a row is displayed for each reason.
EXECUTE DBMS_MVIEW.EXPLAIN_MVIEW ('SH.CAL_MONTH_SALES_MV'); SELECT capability_name, possible, SUBSTR(related_text,1,8) AS rel_text, SUBSTR(msgtxt,1,60) AS msgtxt FROM MV_CAPABILITIES_TABLE ORDER BY seq;
CAPABILITY_NAME P REL_TEXT MSGTXT --------------- - -------- ------ PCT N REFRESH_COMPLETE Y REFRESH_FAST N REWRITE Y PCT_TABLE N SALES no partition key or PMARKER in select list PCT_TABLE N TIMES relation is not a partitioned table REFRESH_FAST_AFTER_INSERT N SH.TIMES mv log must have new values REFRESH_FAST_AFTER_INSERT N SH.TIMES mv log must have ROWID REFRESH_FAST_AFTER_INSERT N SH.TIMES mv log does not have all necessary columns REFRESH_FAST_AFTER_INSERT N SH.SALES mv log must have new values REFRESH_FAST_AFTER_INSERT N SH.SALES mv log must have ROWID REFRESH_FAST_AFTER_INSERT N SH.SALES mv log does not have all necessary columns REFRESH_FAST_AFTER_ONETAB_DML N DOLLARS SUM(expr) without COUNT(expr) REFRESH_FAST_AFTER_ONETAB_DML N see the reason why REFRESH_FAST_AFTER_INSERT is disabled REFRESH_FAST_AFTER_ONETAB_DML N COUNT(*) is not present in the select list REFRESH_FAST_AFTER_ONETAB_DML N SUM(expr) without COUNT(expr) REFRESH_FAST_AFTER_ANY_DML N see the reason why REFRESH_FAST_AFTER_ONETAB_DML is disabled REFRESH_FAST_AFTER_ANY_DML N SH.TIMES mv log must have sequence REFRESH_FAST_AFTER_ANY_DML N SH.SALES mv log must have sequence REFRESH_PCT N PCT is not possible on any of the detail tables in the materialized view REWRITE_FULL_TEXT_MATCH Y REWRITE_PARTIAL_TEXT_MATCH Y REWRITE_GENERAL Y REWRITE_PCT N PCT is not possible on any detail tables
| See Also:
Chapter 14, "Maintaining the Data Warehouse" and Chapter 22, "Query Rewrite" for further details about PCT |
Table 8-6 lists explanations for values in the CAPABILITY_NAME column.
Table 8-7 lists the semantics for RELATED_TEXT and RELATED_NUM columns.
|
 Copyright © 1996, 2002 Oracle Corporation. All Rights Reserved. |
|

