 | Chapter 11 Troubleshooting TCP/IP |  |

| Chapter 11 Troubleshooting TCP/IP | |
The "no answer" and "cannot connect" errors indicate a problem in the lower layers of the network protocols. If the preliminary tests point to this type of problem, concentrate your testing on routing and on the network interface. Use the ifconfig, netstat, and arp commands to test the Network Access Layer.
ifconfig checks the network interface configuration. Use this command to verify the user's configuration if the user's system has been recently configured, or if the user's system cannot reach the remote host while other systems on the same network can.
When ifconfig is entered with an interface name and no other arguments, it displays the current values assigned to that interface. For example, checking interface le0 on a Solaris system gives this report:
%ifconfig le0le0: flags=863<UP,BROADCAST,NOTRAILERS,RUNNING,MULTICAST> mtu 1500 inet 172.16.55.105 netmask ffffff00 broadcast 172.16.55.255
The ifconfig command displays two lines of output. The first line of the display shows the interface's name and its characteristics. Check for these characteristics:
The interface is enabled for use. If the interface is "down," have the system's superuser bring the interface "up" with the ifconfig command (e.g., ifconfig le0 up). If the interface won't come up, replace the interface cable and try again. If it still fails, have the interface hardware checked.
This interface is operational. If the interface is not "running," the driver for this interface may not be properly installed. The system administrator should review all of the steps necessary to install this interface, looking for errors or missed steps.
The second line of ifconfig output shows the IP address, the subnet mask (written in hexadecimal), and the broadcast address. Check these three fields to make sure the network interface is properly configured.
Two common interface configuration problems are misconfigured subnet masks and incorrect IP addresses. A bad subnet mask is indicated when the host can reach other hosts on its local subnet and remote hosts on distant networks, but it cannot reach hosts on other local subnets. ifconfig quickly reveals if a bad subnet mask is set.
An incorrectly set IP address can be a subtle problem. If the network part of the address is incorrect, every ping will fail with the "no answer" error. In this case, using ifconfig will reveal the incorrect address. However, if the host part of the address is wrong, the problem can be more difficult to detect. A small system, such as a PC that only connects out to other systems and never accepts incoming connections, can run for a long time with the wrong address without its user noticing the problem. Additionally, the system that suffers the ill effects may not be the one that is misconfigured. It is possible for someone to accidentally use your IP address on his system, and for his mistake to cause your system intermittent communications problems. An example of this problem is discussed later. This type of configuration error cannot be discovered by ifconfig, because the error is on a remote host. The arp command is used for this type of problem.
The arp command is used to analyze problems with IP to Ethernet address translation. The arp command has three useful options for troubleshooting:
Display all ARP entries in the table.
hostnameDelete an entry from the ARP table.
hostname ether-addressAdd a new entry to the table.
With these three options you can view the contents of the ARP table, delete a problem entry, and install a corrected entry. The ability to install a corrected entry is useful in "buying time" while you look for the permanent fix.
Use arp if you suspect that incorrect entries are getting into the address resolution table. One clear indication of problems with the ARP table is a report that the "wrong" host responded to some command, like ftp or telnet. Intermittent problems that affect only certain hosts can also indicate that the ARP table has been corrupted. ARP table problems are usually caused by two systems using the same IP address. The problems appear intermittent, because the entry that appears in the table is the address of the host that responded quickest to the last ARP request. Sometimes the "correct" host responds first, and sometimes the "wrong" host responds first.
If you suspect that two systems are using the same IP address, display the address resolution table with the arp -a command. Here's an example from a Solaris system: [3]
[3] The format in which the ARP table is displayed may vary slightly between systems.
%arp -aNet to Media Table Device IP Address Mask Flags Phys Addr ------ -------------------- --------------- ----- --------------- le0 peanut.nuts.com 255.255.255.255 08:00:20:05:21:33 le0 pecan.nuts.com 255.255.255.255 00:00:0c:e0:80:b1 le0 almond.nuts.com 255.255.255.255 SP 08:00:20:22:fd:51 le0 BASE-ADDRESS.MCAST.NET 240.0.0.0 SM 01:00:5e:00:00:00
It is easiest to verify that the IP and Ethernet address pairs are correct if you have a record of each host's correct Ethernet address. For this reason you should record each host's Ethernet and IP address when it is added to your network. If you have such a record, you'll quickly see if anything is wrong with the table.
If you don't have this type of record, the first three bytes of the Ethernet address can help you to detect a problem. The first three bytes of the address identify the equipment manufacturer. A list of these identifying prefixes is found in the Assigned Numbers RFC, in the section entitled "Ethernet Vendor Address Components." This information is also available at ftp://ftp.isi.edu/in-notes/iana/assignments/ethernet-numbers.
From the vendor prefixes we see that two of the ARP entries displayed in our example are Sun systems (8:0:20). If pecan is also supposed to be a Sun, the 0:0:0c Cisco prefix indicates that a Cisco router has been mistakenly configured with pecan's IP address.
If neither checking a record of correct assignments nor checking the manufacturer prefix helps you identify the source of the errant ARP, try using telnet to connect to the IP address shown in the ARP entry. If the device supports telnet, the login banner might help you identify the incorrectly configured host.
A user called in asking if the server was down, and reported the following problem. The user's workstation, called cashew, appeared to "lock up" for minutes at a time when certain commands were used, while other commands worked with no problems. The network commands that involved the NIS name server all caused the lock-up problem, but some unrelated commands also caused the problem. The user reported seeing the error message:
NFS getattr failed for server almond: RPC: Timed out
The server almond was providing cashew with NIS and NFS services. The commands that failed on cashew were commands that required NIS service, or that were stored in the centrally maintained /usr/local directory exported from almond. The commands that ran correctly were installed locally on the user's workstation. No one else reported a problem with the server, and we were able to ping cashew from almond and get good responses.
We had the user check the /usr/adm/messages file for recent error messages, and she discovered this:
Mar 6 13:38:23 cashew vmunix: duplicate IP address!! sent from ethernet address: 0:0:c0:4:38:1a
This message indicates that the workstation detected another host on the Ethernet responding to its IP address. The "imposter" used the Ethernet address 0:0:c0:4:38:1a in its ARP response. The correct Ethernet address for cashew is 8:0:20:e:12:37.
We checked almond's ARP table and found that it had the incorrect ARP entry for cashew. We deleted the bad cashew entry with the arp -d command, and installed the correct entry with the -s option, as shown below:
#arp -d cashewcashew (172.16.180.130) deleted #arp -s cashew 8:0:20:e:12:37
ARP entries received via the ARP protocol are temporary. The values are held in the table for a finite lifetime and are deleted when that lifetime expires. New values are then obtained via the ARP protocol. Therefore, if some remote interfaces change, the local table adjusts and communications continue. Usually this is a good idea, but if someone is using the wrong IP address, that bad address can keep reappearing in the ARP table even if it is deleted. However, manually entered values are permanent; they stay in the table and can only be deleted manually. This allowed us to install a correct entry in the table, without worrying about it being overwritten by a bad address.
This quick fix resolved cashew's immediate problem, but we still needed to find the culprit. We checked the /etc/ethers file to see if we had an entry for Ethernet address 0:0:c0:4:38:1a, but we didn't. From the first three bytes of this address, 0:0:c0, we knew that the device was a Western Digital card. Since our network has only UNIX workstations and PCs, we assumed the Western Digital card was installed in a PC. We also guessed that the problem address was recently installed because the user had never had the problem before. We sent out an urgent announcement to all users asking if anyone had recently installed a new PC, reconfigured a PC, or installed TCP/IP software on a PC. We got one response. When we checked his system, we found out that he had entered the address 172.16.180.130 when he should have entered 172.16.180.138. The address was corrected and the problem did not recur.
Nothing fancy was needed to solve this problem. Once we checked the error messages, we knew what the problem was and how to solve it. Involving the entire network user community allowed us to quickly locate the problem system and to avoid a room-to-room search for the PC. Reluctance to involve users and make them part of the solution is one of the costliest, and most common, mistakes made by network administrators.
If the preliminary tests lead you to suspect that the connection to the local area network is unreliable, the netstat -i command can provide useful information. The example below shows the output from the netstat -i command:
%netstat -iName Mtu Net/Dest Address Ipkts Ierrs Opkts Oerrs Collis Queue le0 1500 nuts.com almond 442697 2 633424 2 50679 0 lo0 1536 loopback localhost 53040 0 53040 0 0 0
The line for the loopback interface, lo0, can be ignored. Only the line for the real network interface is significant, and only the last five fields on that line provide significant troubleshooting information.
Let's look at the last field first. There should be no packets queued (Queue) that cannot be transmitted. If the interface is up and running, and the system cannot deliver packets to the network, suspect a bad drop cable or a bad interface. Replace the cable and see if the problem goes away. If it doesn't, call the vendor for interface hardware repairs.
The input errors (Ierrs) and the output errors (Oerrs) should be close to 0. Regardless of how much traffic has passed through this interface, 100 errors in either of these fields is high. High output errors could indicate a saturated local network or a bad physical connection between the host and the network. High input errors could indicate that the network is saturated, the local host is overloaded, or there is a physical network problem. Tools, such as ping statistics or a cable tester, can help you determine if it is a physical network problem. Evaluating the collision rate can help you determine if the local Ethernet is saturated.
A high value in the collision field (Collis) is normal, but if the percentage of output packets that result in a collision is too high, it indicates that the network is saturated. Collision rates greater than 5% bear watching. If high collision rates are seen consistently, and are seen among a broad sampling of systems on the network, you may need to subdivide the network to reduce traffic load.
Collision rates are a percentage of output packets. Don't use the total number of packets sent and received; use the values in the Opkts and Collis fields when determining the collision rate. For example, the output in the netstat sample above shows 50679 collisions out of 633424 outgoing packets. That's a collision rate of 8%. This sample network could be overworked; check the statistics on other hosts on this network. If the other systems also show a high collision rate, consider subdividing this network.
To reduce the collision rate, you must reduce the amount of traffic on the network segment. A simple way to do this is to create multiple segments out of the single segment. Each new segment will have fewer hosts and, therefore, less traffic. We'll see, however, that it's not quite this simple.
The most effective way to subdivide an Ethernet is to install an Ethernet switch. Each port on the switch is essentially a separate Ethernet. So a 16-port switch gives you 16 Ethernets to work with when balancing the load. On most switches the ports can be used in a variety of ways (see Figure 11.1 Lightly used systems can be attached to a hub that is then attached to one of the switch ports to allow the systems to share a single segment. Servers and demanding systems can be given dedicated ports so that they don't need to share a segment with anyone. Additionally, some switches provide a few Fast Ethernet 100 Mbps ports. These are called asymmetric switches because different ports operate at different speeds. Use the Fast Ethernet ports to connect heavily used servers. If you're buying a new switch, buy a 10/100 switch with auto-sensing ports. This allows every port to be used at either 100 Mbps or at 10 Mbps, which give you the maximum configuration flexibility.
Figure 11.1 shows an 8-port 10/100 Ethernet switch. Ports 1 and 2 are wired to Ethernet hubs. A few systems are connected to each hub. When new systems are added they are distributed evenly among the hubs to prevent any one segment from becoming overloaded. Additional hubs can be added to the available switch ports for future expansion. Port 4 attaches a demanding system with its own private segment. Port 6 operates at 100 Mbps and attaches a heavily used server. A port can be reserved for a future 100 Mbps connection to a second 10/100 Ethernet switch for even more expansion.
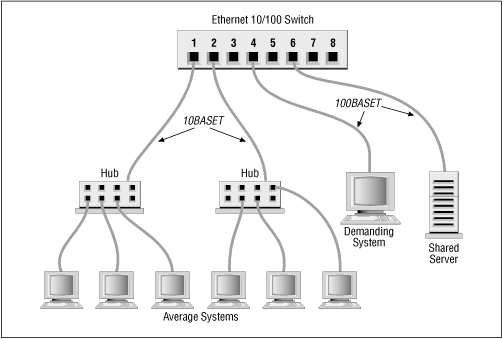
Before allocating the ports on your switch, evaluate what services are in demand, and who talks to whom. Then develop a plan that reduces the amount of traffic flowing over any segment. For example, if the demanding system on Port 4 uses lots of bandwidth because it is constantly talking to one of the systems on Port 1, all of the systems on Port 1 will suffer because of this traffic. The computer that the demanding system communicates with should be moved to one of the vacant ports or to the same port (4) as the demanding system. Use your switch to the greatest advantage by balancing the load.
Should you segment an old coaxial cable Ethernet by cutting the cable and joining it back together through a router or a bridge? No. If you have an old network that is finally reaching saturation, it is time to install a new network built on a more robust technology. A shared media network, a network where everyone is on the same cable (in this example, a coaxial cable Ethernet) is an accident waiting to happen. Design a network that a user cannot bring down by merely disconnecting his system, or even by accidentally cutting a wire in his office. Use Unshielded Twisted Pair (UTP) cable, ideally Category 5 cable, to create a 10BaseT Ethernet or 100BaseT Fast Ethernet that wires equipment located in the user's office to a hub securely stored in a wire closet. The network components in the user's office should be sufficiently isolated from the network so that damage to those components does not damage the entire network. The new network will solve your collision problem and reduce the amount of hardware troubleshooting you are called upon to do.
Some of the tests discussed in this section can show a network hardware problem. If a hardware problem is indicated, contact the people responsible for the hardware. If the problem appears to be in a leased telephone line, contact the telephone company. If the problem appears to be in a wide area network, contact the management of that network. Don't sit on a problem expecting it to go away. It could easily get worse.
If the problem is in your local area network, you will have to handle it yourself. Some tools, such as the cable tester described above, can help. But frequently the only way to approach a hardware problem is by brute force - disconnecting pieces of hardware until you find the one causing the problem. It is most convenient to do this at the switch or hub. If you identify a device causing the problem, repair or replace it. Remember that the problem can be the cable itself, rather than any particular device.
|  | |
| 11.3 Testing Basic Connectivity |  | 11.5 Checking Routing |