| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|





|
View PDF |
| Oracle9i Database Performance Tuning Guide and Reference Release 2 (9.2) Part Number A96533-02 |
|
|
View PDF |
This chapter discusses Oracle's rule-based optimizer (RBO). In general, always use the cost-based approach. The rule-based approach is available for backward compatibility.
|
Note: Oracle Corporation strongly advises the use of cost-based optimization. Rule-based optimization will be deprecated in a future release. |
This chapter contains the following sections:
Although Oracle supports the rule-based optimizer, you should design new applications to use the cost-based optimizer (CBO). You should also use the CBO for data warehousing applications, because the CBO supports enhanced features for DSS. Many new performance features, such as partitioned tables, improved star query processing, and materialized views, are only available with the CBO.
If OPTIMIZER_MODE=CHOOSE, if statistics do not exist, and if you do not add hints to SQL statements, then SQL statements use the RBO. You can use the RBO to access both relational data and object types. If OPTIMIZER_MODE=FIRST_ROWS, FIRST_ROWS_n, or ALL_ROWS and no statistics exist, then the CBO uses default statistics. Migrate existing applications to use the cost-based approach.
You can enable the CBO on a trial basis simply by collecting statistics. You can then return to the RBO by deleting the statistics or by setting either the value of the OPTIMIZER_MODE initialization parameter or the OPTIMIZER_MODE clause of the ALTER SESSION statement to RULE. You can also use this value if you want to collect and examine statistics for data without using the cost-based approach.
| See Also:
Chapter 3, "Gathering Optimizer Statistics" for an explanation of how to gather statistics |
Using the RBO, the optimizer chooses an execution plan based on the access paths available and the ranks of these access paths. Oracle's ranking of the access paths is heuristic. If there is more than one way to execute a SQL statement, then the RBO always uses the operation with the lower rank. Usually, operations of lower rank execute faster than those associated with constructs of higher rank.
The list shows access paths and their ranking:
RBO Path 1: Single Row by Rowid
RBO Path 2: Single Row by Cluster Join
RBO Path 3: Single Row by Hash Cluster Key with Unique or Primary Key
RBO Path 4: Single Row by Unique or Primary Key
RBO Path 7: Indexed Cluster Key
RBO Path 9: Single-Column Indexes
RBO Path 10: Bounded Range Search on Indexed Columns
RBO Path 11: Unbounded Range Search on Indexed Columns
RBO Path 13: MAX or MIN of Indexed Column
RBO Path 14: ORDER BY on Indexed Column
Each of the following sections describes an access path, discusses when it is available, and shows the output generated for it by the EXPLAIN PLAN statement.
This access path is available only if the statement's WHERE clause identifies the selected rows by rowid or with the CURRENT OF CURSOR embedded SQL syntax supported by the Oracle precompilers. To execute the statement, Oracle accesses the table by rowid.
For example:
SELECT * FROM emp WHERE ROWID = 'AAAA7bAA5AAAA1UAAA';
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP
This access path is available for statements that join tables stored in the same cluster if both of the following conditions are true:
WHERE clause contains conditions that equate each column of the cluster key in one table with the corresponding column in the other table.WHERE clause also contains a condition that guarantees the join returns only one row. Such a condition is likely to be an equality condition on the column(s) of a unique or primary key.These conditions must be combined with AND operators. To execute the statement, Oracle performs a nested loops operation.
For example, in the following statement, the emp and dept tables are clustered on the deptno column, and the empno column is the primary key of the emp table:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno AND emp.empno = 7900;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS BY ROWID EMP INDEX UNIQUE SCAN PK_EMP TABLE ACCESS CLUSTER DEPT
pk_emp is the name of an index that enforces the primary key.
This access path is available if both of the following conditions are true:
WHERE clause uses all columns of a hash cluster key in equality conditions. For composite cluster keys, the equality conditions must be combined with AND operators.To execute the statement, Oracle applies the cluster's hash function to the hash cluster key value specified in the statement to obtain a hash value. Oracle then uses the hash value to perform a hash scan on the table.
For example:
In the following statement, the orders and line_items tables are stored in a hash cluster, and the orderno column is both the cluster key and the primary key of the orders table:
SELECT * FROM orders WHERE orderno = 65118968;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS HASH ORDERS
This access path is available if the statement's WHERE clause uses all columns of a unique or primary key in equality conditions. For composite keys, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a unique scan on the index on the unique or primary key to retrieve a single rowid, and then accesses the table by that rowid.
For example:
In the following statement, the empno column is the primary key of the emp table:
SELECT * FROM emp WHERE empno = 7900;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP INDEX UNIQUE SCAN PK_EMP
pk_emp is the name of the index that enforces the primary key.
This access path is available for statements that join tables stored in the same cluster if the statement's WHERE clause contains conditions that equate each column of the cluster key in one table with the corresponding column in the other table. For a composite cluster key, the equality conditions must be combined with AND operators. To execute the statement, Oracle performs a nested loops operation.
For example:
In the following statement, the emp and dept tables are clustered on the deptno column:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT NESTED LOOPS TABLE ACCESS FULL DEPT TABLE ACCESS CLUSTER EMP
This access path is available if the statement's WHERE clause uses all the columns of a hash cluster key in equality conditions. For a composite cluster key, the equality conditions must be combined with AND operators. To execute the statement, Oracle applies the cluster's hash function to the hash cluster key value specified in the statement to obtain a hash value. Oracle then uses this hash value to perform a hash scan on the table.
For example: In the following statement, the orders and line_items tables are stored in a hash cluster, and the orderno column is the cluster key:
SELECT * FROM line_items WHERE orderno = 65118968;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS HASH LINE_ITEMS
This access path is available if the statement's WHERE clause uses all the columns of an indexed cluster key in equality conditions. For a composite cluster key, the equality conditions must be combined with AND operators.
To execute the statement, Oracle performs a unique scan on the cluster index to retrieve the rowid of one row with the specified cluster key value. Oracle then uses that rowid to access the table with a cluster scan. Because all rows with the same cluster key value are stored together, the cluster scan requires only a single rowid to find them all.
For example:
In the following statement, the emp table is stored in an indexed cluster, and the deptno column is the cluster key:
SELECT * FROM emp WHERE deptno = 10;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS CLUSTER EMP INDEX UNIQUE SCAN PERS_INDEX
pers_index is the name of the cluster index.
This access path is available if the statement's WHERE clause uses all columns of a composite index in equality conditions combined with AND operators. To execute the statement, Oracle performs a range scan on the index to retrieve rowids of the selected rows, and then accesses the table by those rowids.
For example:
In the following statement, there is a composite index on the job and deptno columns:
SELECT * FROM emp WHERE job = 'CLERK' AND deptno = 30;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN JOB_DEPTNO_INDEX
job_deptno_index is the name of the composite index on the job and deptno columns.
This access path is available if the statement's WHERE clause uses the columns of one or more single-column indexes in equality conditions. For multiple single-column indexes, the conditions must be combined with AND operators.
If the WHERE clause uses the column of only one index, then Oracle executes the statement by performing a range scan on the index to retrieve the rowids of the selected rows, and then accesses the table by these rowids.
For example:
In the following statement, there is an index on the job column of the emp table:
SELECT * FROM emp WHERE job = 'ANALYST';
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN JOB_INDEX
job_index is the index on emp.job.
If the WHERE clauses uses columns of many single-column indexes, then Oracle executes the statement by performing a range scan on each index to retrieve the rowids of the rows that satisfy each condition. Oracle then merges the sets of rowids to obtain a set of rowids of rows that satisfy all conditions. Oracle then accesses the table using these rowids.
Oracle can merge up to five indexes. If the WHERE clause uses columns of more than five single-column indexes, then Oracle merges five of them, accesses the table by rowid, and then tests the resulting rows to determine whether they satisfy the remaining conditions before returning them.
In the following statement, there are indexes on both the job and deptno columns of the emp table:
SELECT * FROM emp WHERE job = 'ANALYST' AND deptno = 20;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP AND-EQUAL INDEX RANGE SCAN JOB_INDEX INDEX RANGE SCAN DEPTNO_INDEX
The AND-EQUAL operation merges the rowids obtained by the scans of the job_index and the deptno_index, resulting in a set of rowids of rows that satisfy the query.
This access path is available if the statement's WHERE clause contains a condition that uses either the column of a single-column index or one or more columns that make up a leading portion of a composite index:
column =exprcolumn >[=]exprAND column <[=]exprcolumn BETWEENexprANDexprcolumn LIKE 'c%'
Each of these conditions specifies a bounded range of indexed values that are accessed by the statement. The range is said to be bounded because the conditions specify both its least value and its greatest value. To execute such a statement, Oracle performs a range scan on the index, and then accesses the table by rowid.
This access path is not available if the expression expr references the indexed column.
For example:
In the following statement, there is an index on the sal column of the emp table:
SELECT * FROM emp WHERE sal BETWEEN 2000 AND 3000;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN SAL_INDEX
sal_index is the name of the index on emp.sal.
In the following statement, there is an index on the ename column of the emp table:
SELECT * FROM emp WHERE ename LIKE 'S%';
This access path is available if the statement's WHERE clause contains one of the following conditions that use either the column of a single-column index or one or more columns of a leading portion of a composite index:
WHERE column >[=]exprWHERE column <[=]expr
Each of these conditions specifies an unbounded range of index values accessed by the statement. The range is said to be unbounded, because the condition specifies either its least value or its greatest value, but not both. To execute such a statement, Oracle performs a range scan on the index, and then accesses the table by rowid.
For example:
In the following statement, there is an index on the sal column of the emp table:
SELECT * FROM emp WHERE sal > 2000;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN SAL_INDEX
In the following statement, there is a composite index on the order and line columns of the line_items table:
SELECT * FROM line_items WHERE order > 65118968;
The access path is available, because the WHERE clause uses the order column, a leading portion of the index.
This access path is not available in the following statement, in which there is an index on the order and line columns:
SELECT * FROM line_items WHERE line < 4;
The access path is not available because the WHERE clause only uses the line column, which is not a leading portion of the index.
This access path is available for statements that join tables that are not stored together in a cluster if the statement's WHERE clause uses columns from each table in equality conditions. To execute such a statement, Oracle uses a sort-merge operation. Oracle can also use a nested loops operation to execute a join statement.
| See Also:
"Understanding Joins" for information on these operations |
For example:
In the following statement, the emp and dept tables are not stored in the same cluster:
SELECT * FROM emp, dept WHERE emp.deptno = dept.deptno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT MERGE JOIN SORT JOIN TABLE ACCESS FULL EMP SORT JOIN TABLE ACCESS FULL DEPT
This access path is available for a SELECT statement, and all of the following conditions are true:
MAX or MIN function to select the maximum or minimum value of either the column of a single-column index or the leading column of a composite index. The index cannot be a cluster index. The argument to the MAX or MIN function can be any expression involving the column, a constant, or the addition operator (+), the concatenation operation (||), or the CONCAT function.WHERE clause or GROUP BY clause.To execute the query, Oracle performs a full scan of the index to find the maximum or minimum indexed value. Because only this value is selected, Oracle need not access the table after scanning the index.
For example, in the following statement, there is an index on the sal column of the emp table:
SELECT MAX(sal) FROM emp;
The EXPLAIN PLAN output for this statement might look like this:
0 SELECT STATEMENT Optimizer=CHOOSE 1 0 SORT (AGGREGATE) 2 1 INDEX (FULL SCAN (MIN/MAX)) OF 'SAL_INDEX' (NON-UNIQUE)
This access path is available for a SELECT statement, and all of the following conditions are true:
ORDER BY clause that uses either the column of a single-column index or a leading portion of a composite index. The index cannot be a cluster index.PRIMARY KEY or NOT NULL integrity constraint that guarantees that at least one of the indexed columns listed in the ORDER BY clause contains no nulls.NLS_SORT initialization parameter is set to BINARY.To execute the query, Oracle performs a range scan of the index to retrieve the rowids of the selected rows in sorted order. Oracle then accesses the table by these rowids.
For example:
In the following statement, there is a primary key on the empno column of the emp table:
SELECT * FROM emp ORDER BY empno;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS BY ROWID EMP INDEX RANGE SCAN PK_EMP
pk_emp is the name of the index that enforces the primary key. The primary key ensures that the column does not contain nulls.
This access path is available for any SQL statement, regardless of its WHERE clause conditions, except when its FROM clause contains SAMPLE or SAMPLE BLOCK.
Note that the full table scan is the lowest ranked access path on the list. This means that the RBO always chooses an access path that uses an index if one is available, even if a full table scan might execute faster.
The following conditions make index access paths unavailable:
where column1 and column2 are in the same table.
regardless of whether column is indexed.
where expr is an expression that operates on a column with an operator or function, regardless of whether the column is indexed.
NOT EXISTS subqueryROWNUM pseudocolumn in a viewAny SQL statement that contains only these constructs and no others that make index access paths available must use full table scans.
For example: The following statement uses a full table scan to access the emp table:
SELECT * FROM emp;
The EXPLAIN PLAN output for this statement might look like this:
OPERATION OPTIONS OBJECT_NAME ----------------------------------------------------- SELECT STATEMENT TABLE ACCESS FULL EMP
With the rule-based approach, the optimizer performs the following steps to choose an execution plan for a statement that joins R tables:
Usually, the optimizer does not consider the order in which tables appear in the FROM clause when choosing an execution plan. The optimizer makes this choice by applying the following rules in order:
FROM clause.SQL is a very flexible query language; often, there are many statements you could use to achieve the same goal. Sometimes, the optimizer transforms one such statement into another that achieves the same goal if the second statement can be executed more efficiently.
This section discusses the following topics:
If a query contains a WHERE clause with multiple conditions combined with OR operators, then the optimizer transforms it into an equivalent compound query that uses the UNION ALL set operator if this makes it execute more efficiently:
| See Also:
"Understanding Access Paths for the RBO" and "How the CBO Transforms ORs into Compound Queries" for information on access paths and how indexes make them available |
With the RBO, the optimizer makes this UNION ALL transformation, because each component query of the resulting compound query can be executed using an index. The RBO assumes that executing the compound query using two index scans is faster than executing the original query using a full table scan.
Because SQL is a flexible language, more than one SQL statement can meet the needs of an application. Although two SQL statements can produce the same result, Oracle might process one faster than the other. You can use the results of the EXPLAIN PLAN statement to compare the execution plans and costs of the two statements and determine which is more efficient.
This example shows the execution plans for two SQL statements that perform the same function. Both statements return all the departments in the dept table that have no employees in the emp table. Each statement searches the emp table with a subquery. Assume there is an index, deptno_index, on the deptno column of the emp table.
The first statement and its execution plan:
SELECT dname, deptno FROM dept WHERE deptno NOT IN (SELECT deptno FROM emp);
The execution plan for the transformed statement might look like the illustration in Figure 8-1. The shaded boxes indicate steps that physically retrieve data and the clear boxes indicate steps that operate on data returned from the previous step.
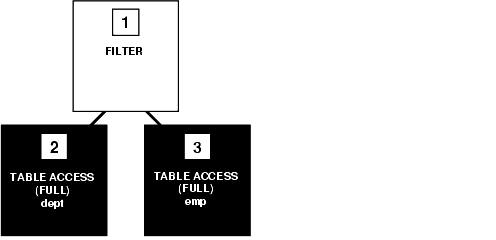
Step 3 of the output indicates that Oracle executes this statement by performing a full table scan of the emp table despite the index on the deptno column. This full table scan can be a time-consuming operation. Oracle does not use the index, because the subquery that searches the emp table does not have a WHERE clause that makes the index available.
However, this SQL statement selects the same rows by accessing the index:
SELECT dname, deptno FROM dept WHERE NOT EXISTS (SELECT deptno FROM emp WHERE dept.deptno = emp.deptno);
The execution plan for the transformed statement might look like the illustration in Figure 8-2. The shaded boxes indicate steps that physically retrieve data and the clear boxes indicate steps that operate on data returned from the previous step.
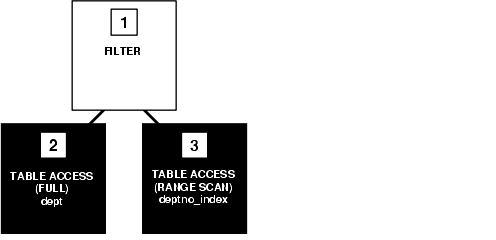
The WHERE clause of the subquery refers to the deptno column of the emp table, so the index deptno_index is used. The use of the index is reflected in step 3 of the execution plan. The index range scan of deptno_index takes less time than the full scan of the emp table in the first statement. Furthermore, the first query performs one full scan of the emp table for every deptno in the dept table. For these reasons, the second SQL statement is faster than the first.
If you have statements in an application that use the NOT IN operator, as the first query in this example does, then consider rewriting them so that they use the NOT EXISTS operator. This allows such statements to use an index if one exists.
|
 Copyright © 2000, 2002 Oracle Corporation. All Rights Reserved. |
|

